Tesla FSD Technical Deep Dive
A comprehensive guide to Tesla Full Self-Driving.

Table of Contents
Introduction
Part 1: Architectural Layout
Part 2: Vector Space
- Transformer
- Inference
- Virtual Camera
- Video Neural Net Architecture
- Recurrent Neural Network
- Tesla Vision Structure
Part 3: Planning and Control
Part 4: Auto labeling and Simulation
Part 5: Updates
- Planning
- Occupancy Network
- Training Infrastructure
- Lanes and Objects
- AI Compiler and Inference
- Auto Labeling
- Simulation
- Data Engine
Part 6: Dojo
Introduction
What is FSD?
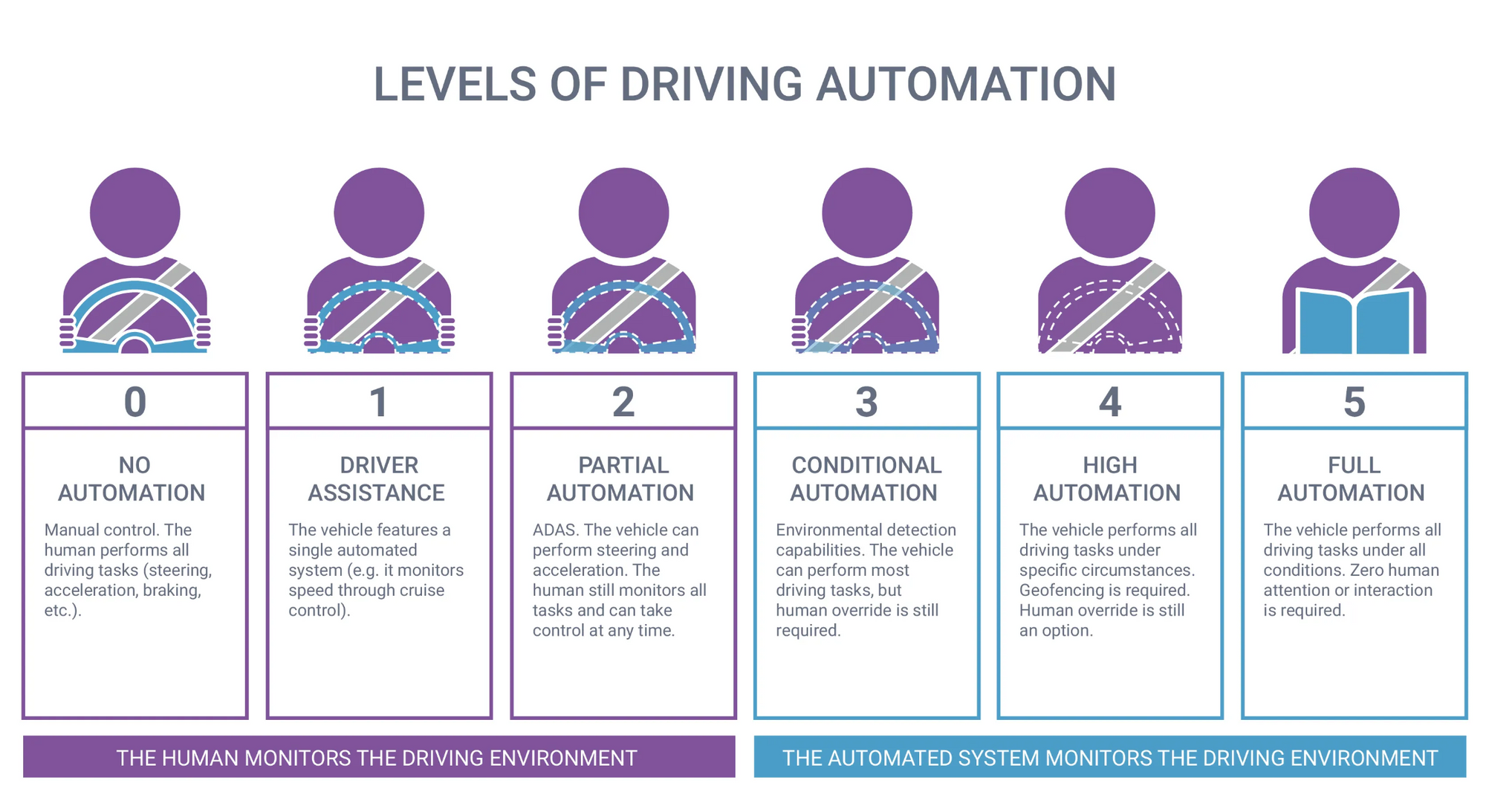
Tesla's Full Self-Driving (FSD) is a set of advanced safety and autonomous driving features that are available for Tesla electric vehicles (EVs). It enables Tesla vehicles to drive semi-autonomously (legally, level 2 autonomy). Currently, FSD is not capable of "fully" self-driving, but Tesla's ultimate goal is to achieve level 5 autonomy.
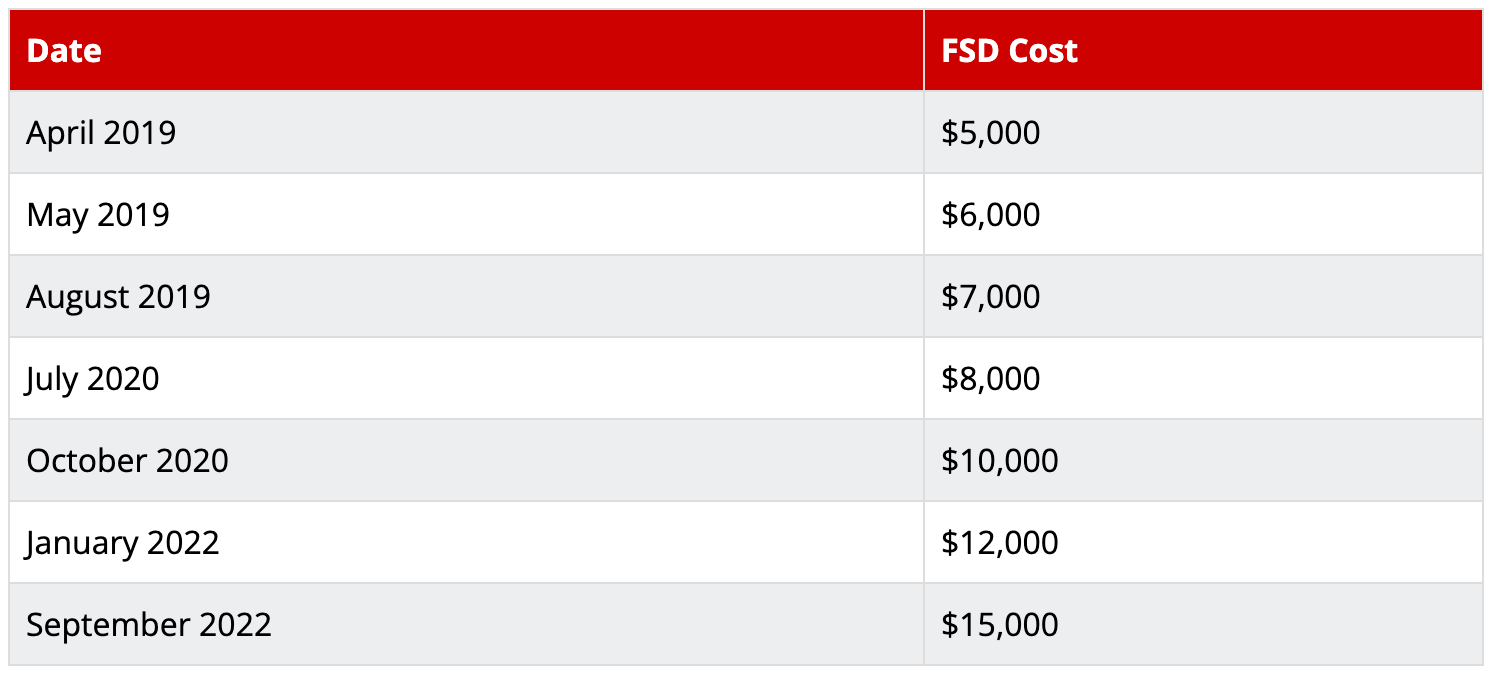
Three tiers of autonomous driving software are available on Tesla EVs: autopilot, enhanced autopilot, and FSD. Autopilot is standard. Enhanced autopilot is a $6,000 software add-on. FSD is a $15,000 software add-on. The price of FSD typically increases several times every year, as the software improves.
Tesla vehicles have been equipped with autopilot functionality for years, however, it was generally limited to freeway driving. FSD allows for city street driving and can automatically start and stop at intersections and stop signs.
Autopilot Features
- Traffic-Aware Cruise Control: Matches the speed of your car to that of the surrounding traffic
- Autosteer: Assists in steering within a clearly marked lane, and uses traffic-aware cruise control
Enhanced Autopilot Features
- Autopilot features.
- Navigate on Autopilot: Actively guides your car from a highway’s on-ramp to off-ramp, including suggesting lane changes, navigating interchanges, automatically engaging the turn signal, and taking the correct exit.
- Auto Lane Change: Assists in moving to an adjacent lane on the highway when Autosteer is engaged.
- Autopark: Helps automatically parallel or perpendicular park your car, with a single touch.
- Summon: Moves your car in and out of a tight space using the mobile app or key.
- Smart Summon: Your car will navigate more complex environments and parking spaces, maneuvering around objects as necessary to come find you in a parking lot.
FSD Features
- Enhanced autopilot features.
- Traffic and Stop Sign Control: Identifies stop signs and traffic lights and automatically slows your car to a stop on approach, with your active supervision
- Autosteer on city streets.
How Does FSD Work?
Tesla's AI team developed advanced machine learning techniques to teach Tesla EVs how to drive autonomously.
Generally, machine learning is a type of applied statistics that focuses heavily on utilizing computers to statistically evaluate complex functions, while placing less importance on determining the confidence intervals surrounding these functions. At its core, machine learning is a way for computers to learn from data. But what does it mean for a computer to "learn"? In his textbook Machine Learning: A Multistrategy Approach, Tom Mitchell defines it as "a computer program that improves its performance on a specific set of tasks, as measured by a specific metric, through experience."
Starting from first principles, if humans can only drive using vision, then it should be possible for a computer to drive using only cameras. Musk has described human drivers as having two cameras that can only look in one direction at a time on a gimbal. Humans lose vision when they blink or look in a different direction and can easily be distracted. Cameras, on the other hand, can run continuously, and with Tesla's 8-camera setup, the entire perimeter of the vehicle is constantly monitored. The 8 cameras on a Tesla are 1280 x 960 12-Bit (HDR) @ 36Hz. Unlike competitors, they forgo using Lidar and mmWave radar.

The figure below shows how the human and primate cerebral cortex process vision. When the information is received by the retina, it is processed through various areas, streams, and layers of the cerebral cortex, leading to biological vision. These areas and organs include the optic chiasm, the lateral geniculate nucleus, the primary visual cortex, the extrastriate cortex, and the inferior temporal area.
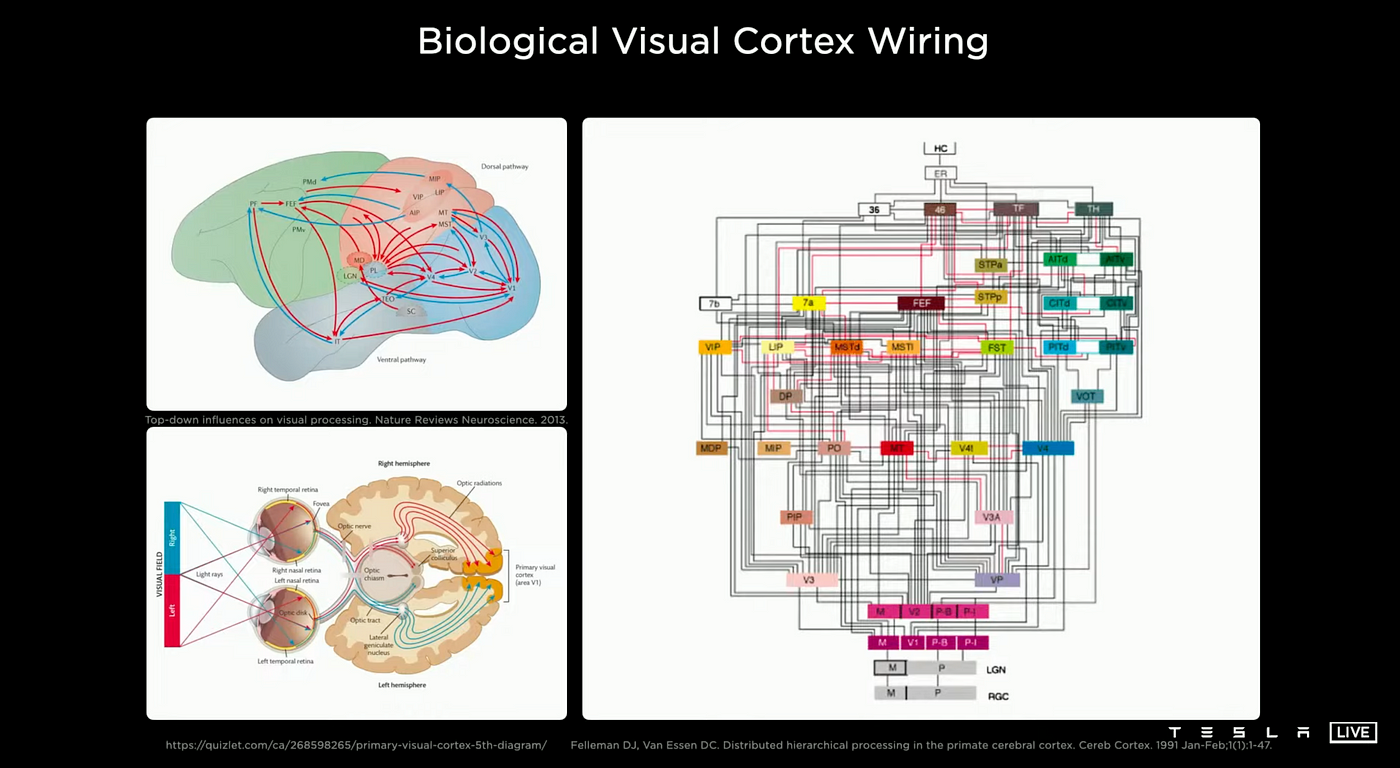
Some of the first learning algorithms that are still recognized today were designed to be computational models of biological learning or models of how the brain learns or could learn. As a result, deep learning has also been referred to as artificial neural networks (ANNs). From this perspective, deep learning models are artificial systems inspired by the biological brain, whether it be the human brain or the brain of another animal. However, it is important to not see deep learning as an attempt to replicate the brain. Modern deep learning is influenced by various fields, particularly applied mathematics concepts like linear algebra, probability, information theory, and numerical optimization.
The video below shows the current version of Tesla Vision. The 8 cameras (Left) around the vehicle generate 3D Vector Space (Right) through neural networks, which represents everything you need for driving, such as lines, edges, curbs, traffic signs, traffic lights, cars; and positions, orientations, depth, velocities of cars.

An ongoing challenge in many real-world applications of artificial intelligence is that the factors affecting the data we observe can be numerous and complex. For example, in an image of a red car taken at night, the individual pixels may appear very dark, and the shape of the car's silhouette can be affected by the angle from which it is viewed. In order to effectively use this data in AI applications, it is necessary to separate out the various factors that are influencing the data and focus on the relevant ones, while discarding or disregarding the others.
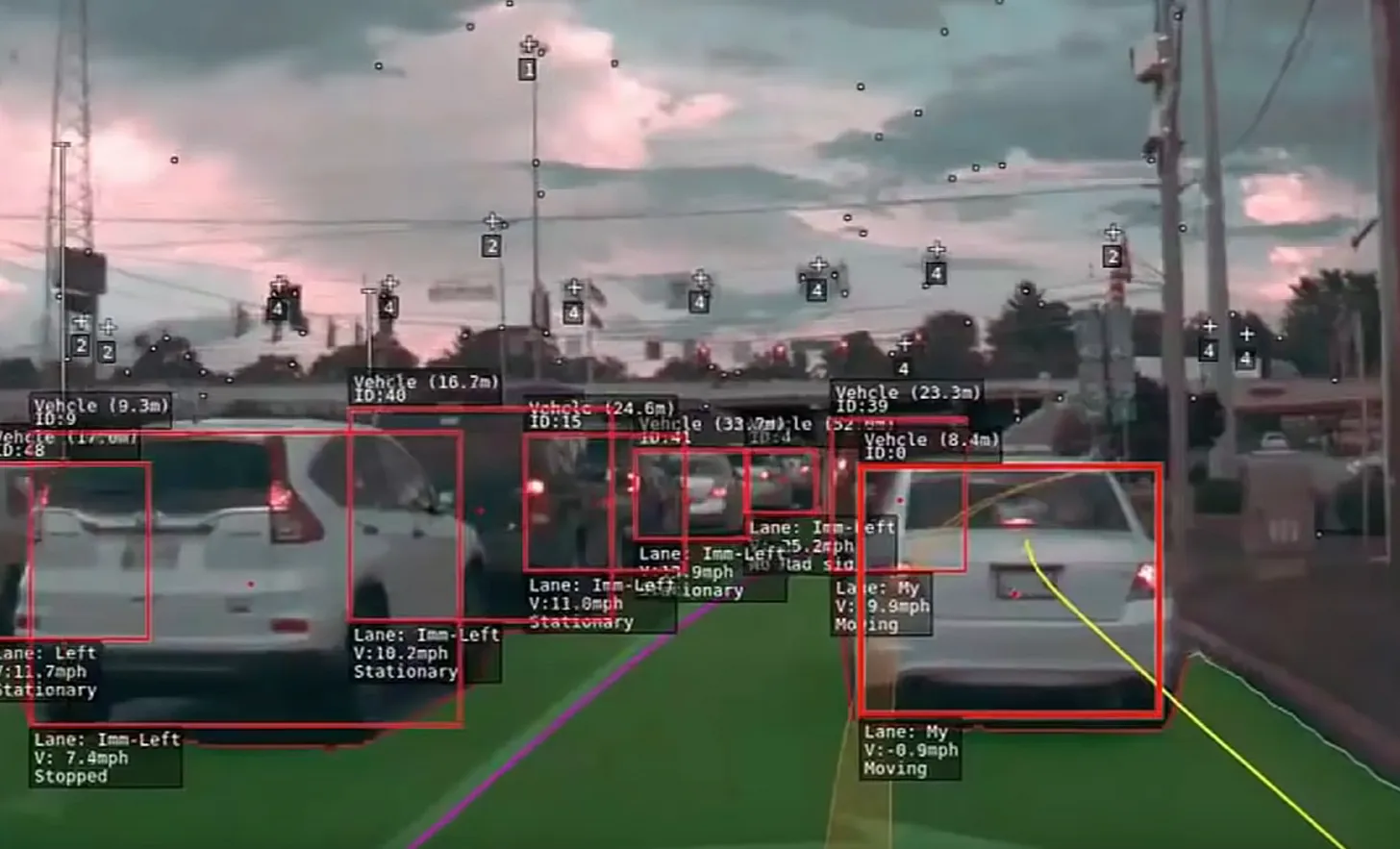
Tesla's Full Self-Driving (FSD) neural network is trained using probability-based methods. For instance, when the vehicle's cameras capture a blurry image of a stop sign, the system will automatically compute the probability that the image represents a stop sign. Then, this probability is compared against a predetermined benchmark. For example, if the probability of the image representing a stop sign is above 98%, the vehicle must stop. However, if the computed probability falls under 95%, the vehicle will not stop. If such predictions prove to be incorrect, the human driver will take over, and Tesla is notified of the incorrect prediction and can use the feedback to improve the system. The company can then fix the issue by adjusting the percentage threshold or the calculation process to help the neural network make more accurate predictions.

How Did Tesla Solve This?
In general, deep learning solves the central problem in representation learning by introducing representations that are expressed in terms of other, simpler representations. Deep learning allows the computer to build complex concepts out of simpler concepts.
Interpreting raw sensory input data, such as an image represented by a series of pixel values, can prove to be a challenging task for a computer. The process of mapping the set of pixels to an object identity is highly complex, making it difficult to learn or evaluate through direct means. However, deep learning addresses this challenge by breaking down the complex mapping into a series of simpler mappings, each represented by a different layer in the model. The input is initially introduced at the visible layer, which contains the variables that can be observed, and then a series of hidden layers work to extract increasingly abstract features from the image. These layers are referred to as "hidden" because the model must determine which concepts are useful in understanding the relationships present in the observed data, rather than being provided with this information.
For example, the first hidden layer may be able to identify edges by comparing the brightness of neighboring pixels, the second hidden layer may look for corners and extended contours, and the third hidden layer may detect entire parts of specific objects. Ultimately, by breaking down the image into smaller, understandable concepts, the model is able to recognize the objects present in the image.
Tesla uses deep probabilistic models in its AI systems. For instance, an AI system looking at an image of a face that has one eye hidden in shadow may initially only detect one eye. After recognizing that there is a face present, the system can then deduce that there is likely a second eye present as well. In this scenario, the concept graph only includes two layers- one for eyes and one for faces. However, the computation graph includes 2n layers if the system repeatedly refines its understanding of each concept based on the presence of the other. This model can be applied to other areas, such as when a Tesla AI system observes part of a car hidden behind a bush, it can predict that the rest of the car is likely there, obscured by the foliage.
As early as 2013, deep networks had spectacular successes in pedestrian detection and yielded superhuman performance in traffic sign classification.
Lidar vs Vision
The development of self-driving vehicles generally follows one of two main approaches: Lidar or vision. Most other companies use Lidar but Tesla uses vision only. This approach relies primarily on cameras as the 'eyes' of the vehicle, unlike the Lidar approach which in addition to cameras and radar, also uses Lidar to guide the vehicle.
One of the key advantages of utilizing Lidar technology in autonomous vehicles is its ability to provide improved depth perception and localization capabilities. Lidar works by emitting laser beams and creating a point cloud map that measures the distance between the car and its surroundings. This map, in conjunction with camera vision, allows the vehicle to more accurately recognize and understand the spatial relationships between objects in its vicinity. Many companies implementing Lidar also choose to use high-definition (HD) maps to supplement their vehicles' perception systems. These maps can be extremely precise and, when used in conjunction with Lidar, allow the car to precisely determine its location and the layout of the road ahead. However, this technology comes with certain downsides, such as cost and the need for regular updates. While Waymo has been able to reduce the cost of Lidar by 90%, it still remains a costly addition to a vehicle at around $7500 per car. Additionally, HD maps are also quite expensive, with unit prices several times higher than traditional navigation maps and the process of creating them is relatively slow. These cost factors make it difficult to scale Lidar-based autonomous driving technology in the short term as long as the prices of Lidar and HD maps are high.
Tesla believes that Lidar is not essential for safe autonomous driving. Humans drive using vision and do not rely on lasers to detect range. Therefore, the argument goes, why should cars require Lidar? Furthermore, the current driving system is designed for drivers with vision, not lasers, and if the vision system is sufficient, there would be no need for Lidar. Additionally, it's worth noting that Tesla's CEO, Elon Musk, has extensive knowledge and experience with Lidar through his other company, Space X, where his team even developed their own Lidar and used it on their rockets. This serves as a further indication of his conviction that Lidar is unnecessary for autonomous driving.
Tesla's approach is based on the belief that in the coming years, its vision system will be advanced enough that other car manufacturers will not be able to justify the cost of including Lidar in their vehicles. While some argue that adding Lidar in addition to cameras would provide an extra layer of safety, the question remains whether consumers will be willing to pay extra for a technology that offers slightly increased safety when the current level of safety is already deemed acceptable. History has shown that people are not willing to pay a premium for "safer" airfare when the standard option is already considered safe. Similarly, if Tesla's vision-based approach proves to be safe enough, Lidar may be considered as a redundant and unnecessary cost.
Currently, it remains uncertain as to when Tesla and other companies utilizing Lidar technology will achieve level 5 autonomy. While both approaches are likely capable of solving the problem of autonomous driving, the question of who will accomplish this goal first remains unresolved. Currently, companies using the Lidar approach, such as Waymo, have already achieved level 4 autonomy in certain locations, while Tesla's current level of autonomy, from a legal perspective, is considered to be level 2. However, some experts have suggested that in terms of technology, Tesla's Full Self-Driving (FSD) beta may be closer to level 3 or even 4.
In August 2021, Tesla gave an in-depth presentation led by Andrej Karpathy, Ashok Elluswamy, and Milan Kovacon on how FSD works. It will be covered in Parts 1-4. In September 2022, Tesla gave an update on their FSD progress, which will be the focus of Parts 5 and 6.
Part 1
Architectural Layout
To understand Tesla's architectural layout, we need to know a few terms:
- Backbone: the feature extracting network, which is used to recognize several objects in a single image and provides rich feature information of objects.
- Head: gives us a feature map representation of the input.
- Neck: used to extract some more elaborate features.
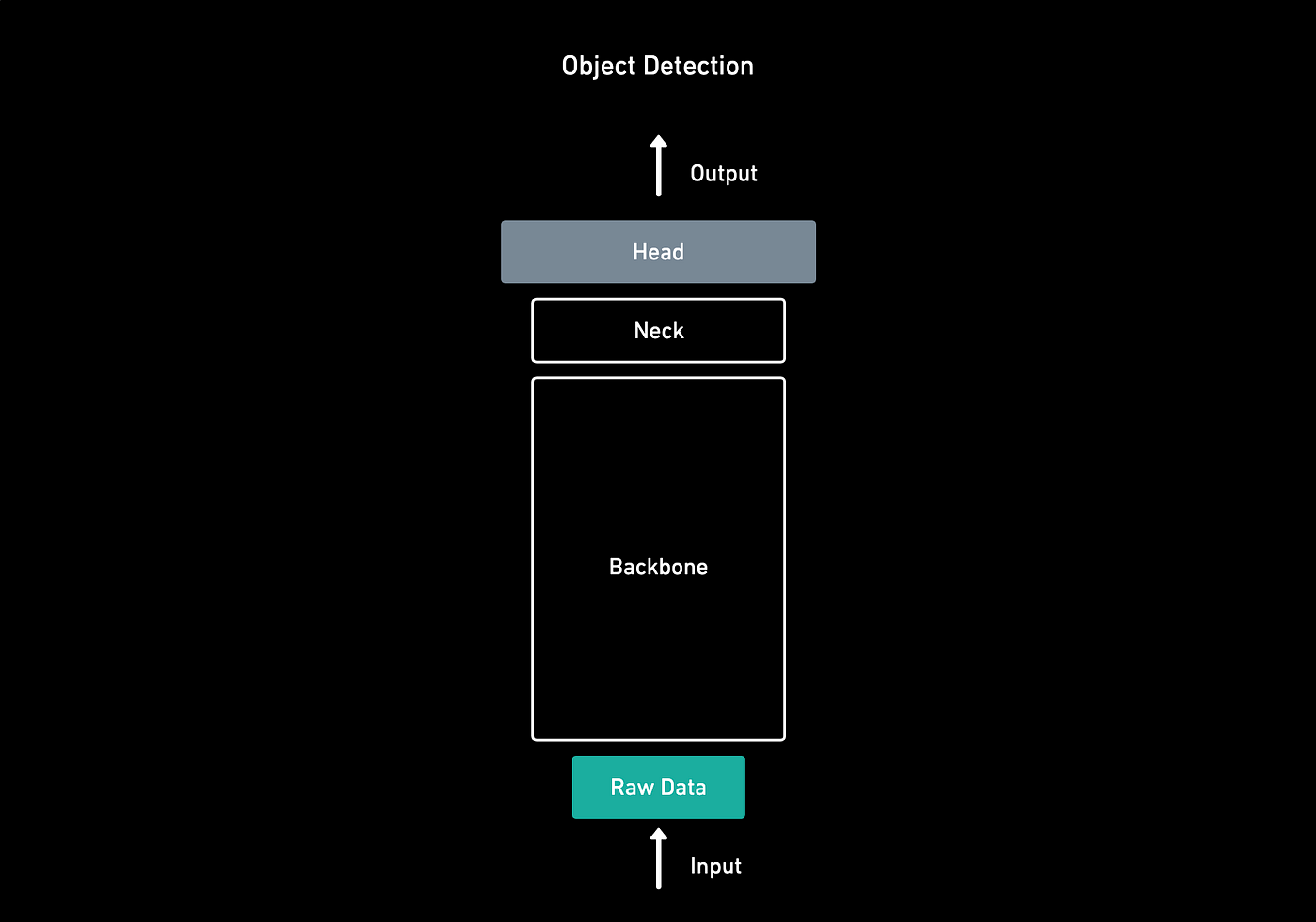
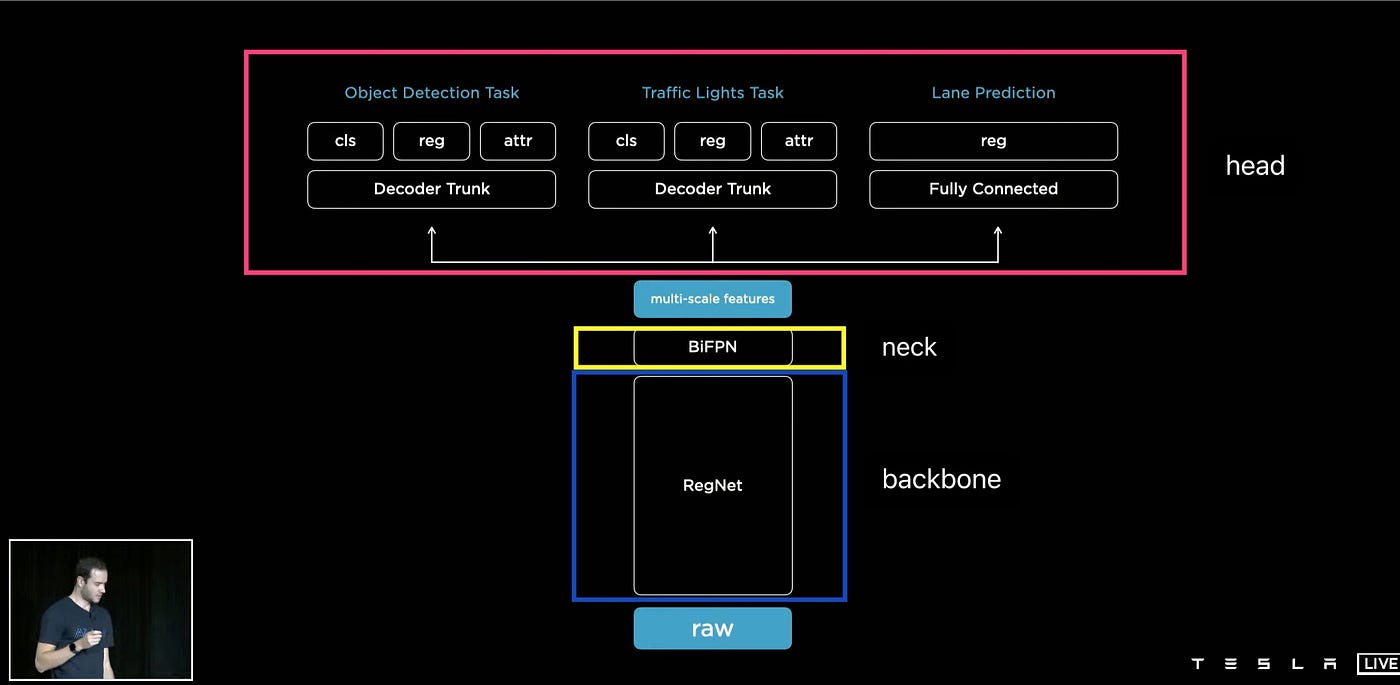
In Tesla's architecture, the backbone is RegNet + ResNet, the neck is BiFPN, and the head is HydraNet.
Neural Network Backbone
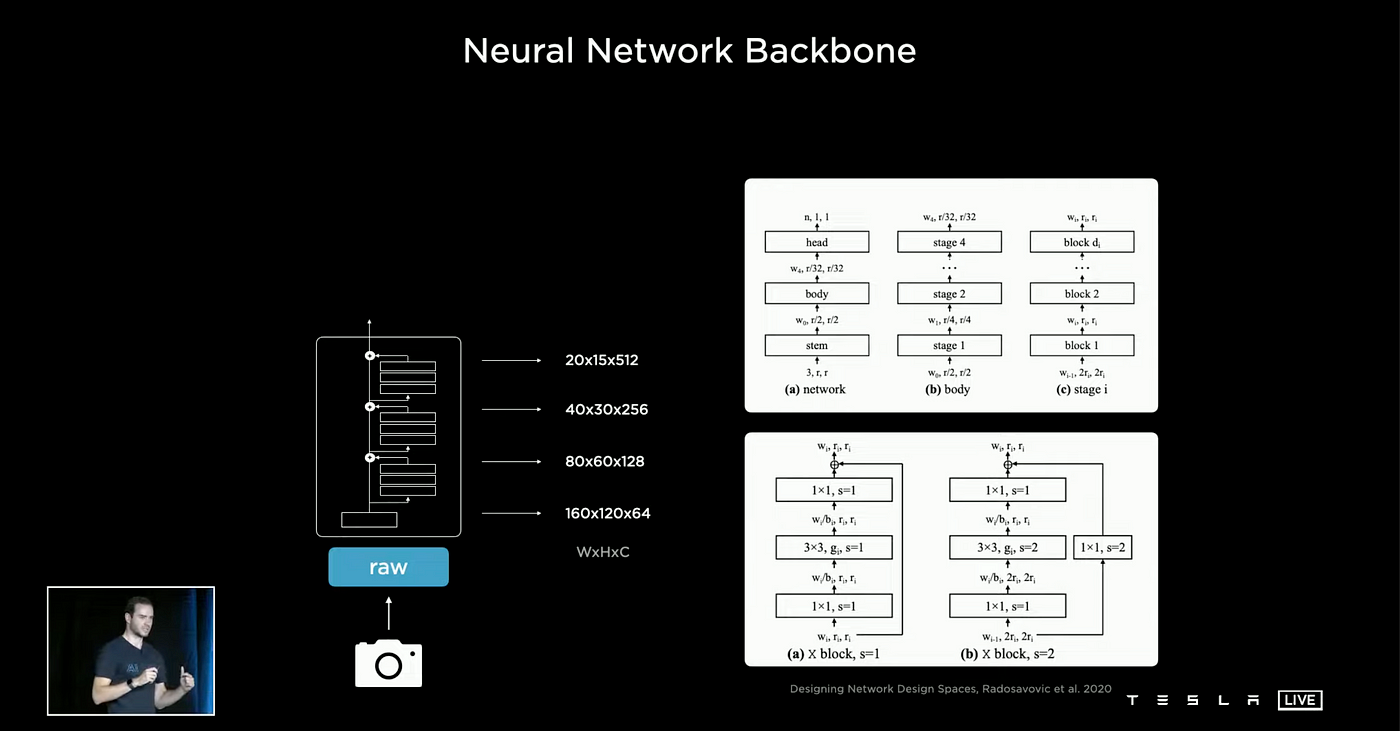
Tesla uses regular network structures (RegNet) designed with residual neural network blocks as its neural network backbone. It uses RegNet because it has a nice design space and a good tradeoff between latency and accuracy.
RegNet was proposed by Facebook in a 2020 research paper Designing Network Design Spaces.
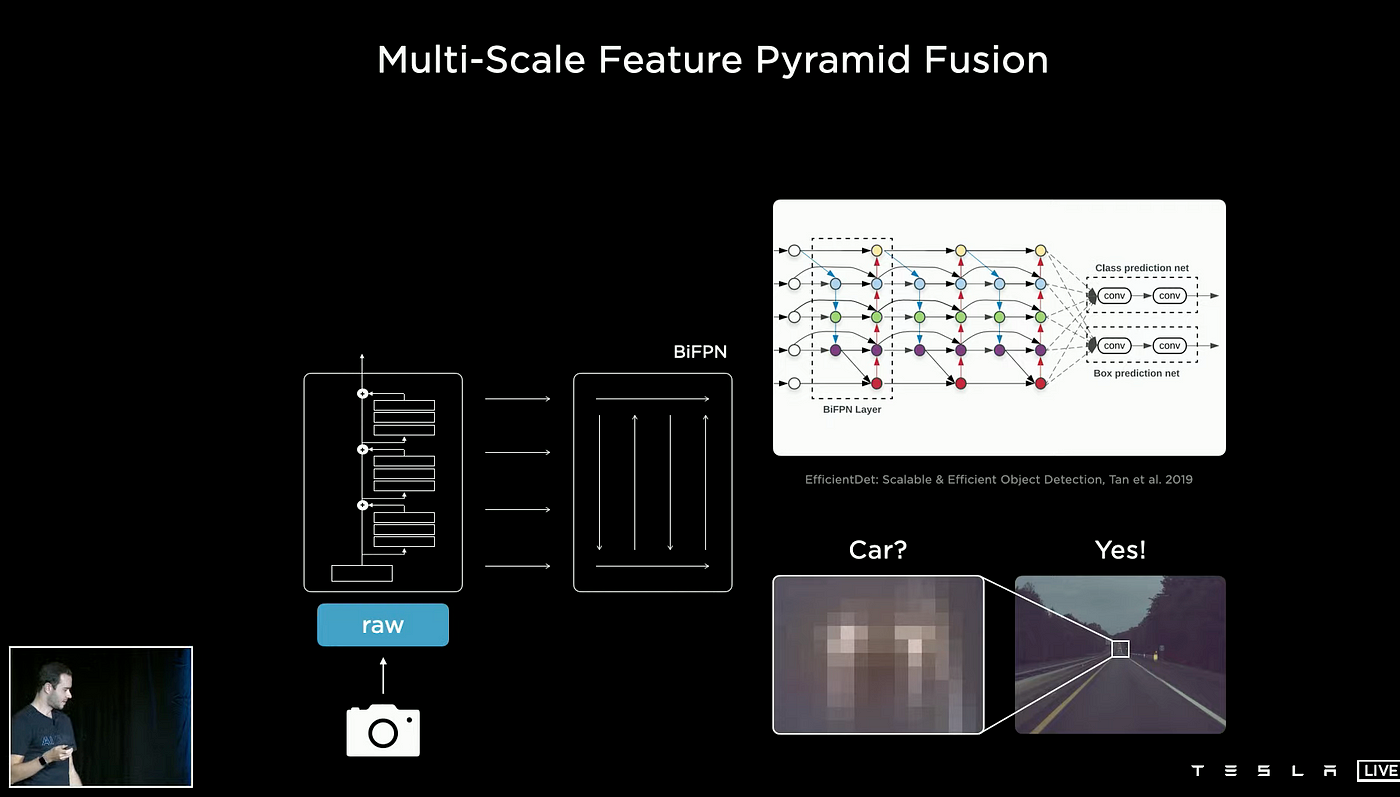
How does Tesla recognize low-resolution objects at a distance, like the car in the figure above? They use bi-directional feature pyramid network (BiFPN) to achieve multi-scale feature pyramid fusion.
Multi-scale feature pyramid fusion is used to combine features from different scales or resolutions of an image or other visual input. It typically involves creating a pyramid of features at different scales, where each scale is a filtered version of the original image at a different resolution. The features at each scale are then combined, or fused, to create a multi-scale representation of the image that can be used for object detection and recognition.
BiFPN was proposed in 2019 by Google Research in the paper, EfficientDet: Scalable and Efficient Object Detection(BiFPN).
BiFPN is a variation of FPN that includes two main enhancements: it performs fusion from the bottom-up in addition to the top-down fusion, and it utilizes weights for each input feature during the fusion process to account for the fact that input features at different resolutions often contribute unequally to the output feature.
Detection Head
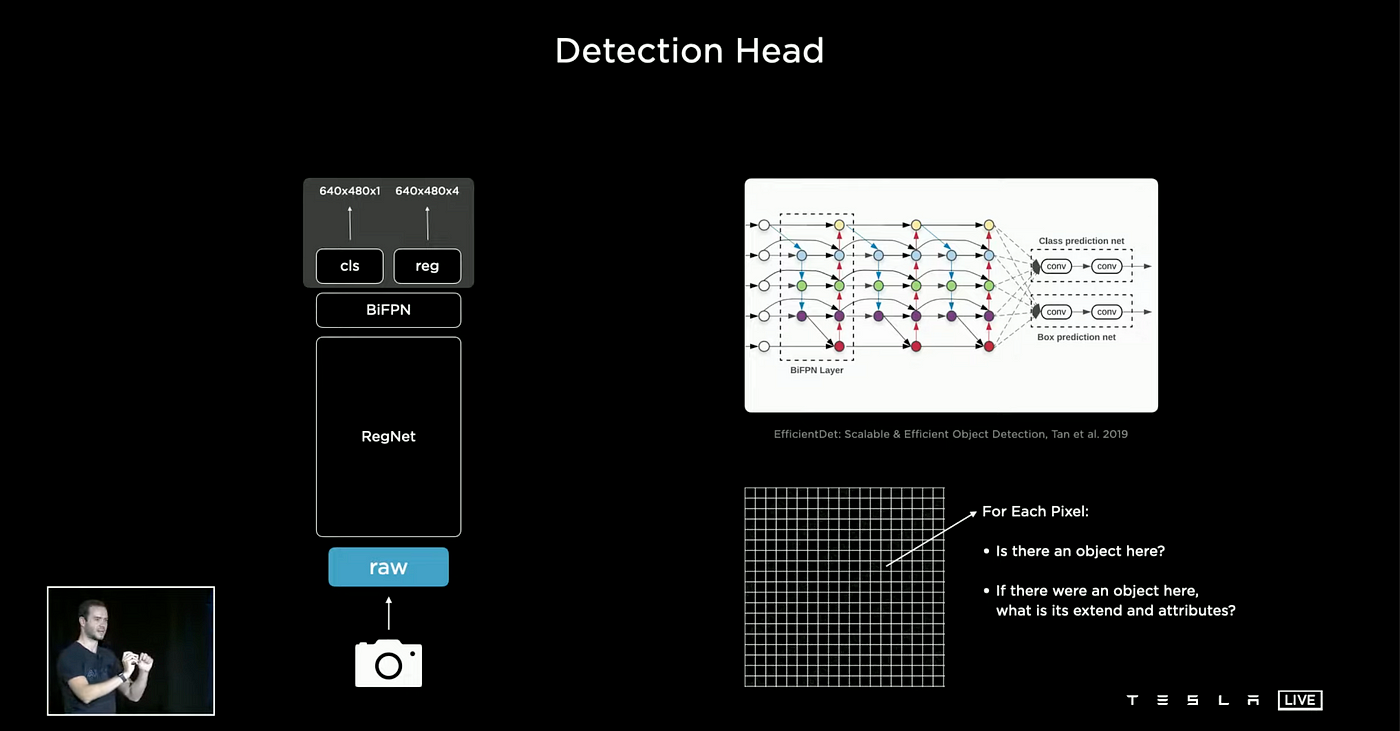
After the BiFPN layer, the network is connected to a detection head. This detection head is made up of several specialized heads that are tailored to specific tasks. For instance, when the Tesla AI team is tasked with detecting cars, they utilize a one-stage object detector that is similar to the YOLO (You Only Look Once) algorithm. This YOLO approach is based on the idea that you only need to examine an image once in order to predict the presence and location of objects, as outlined in the paper “You Only Look Once: Unified, Real-Time Object Detection.”
When a raster is initialized, a binary bit is assigned to each position to indicate the presence or absence of a car. If a car is detected, a set of additional attributes are also recorded, such as the (x, y) coordinates, the width and height of the bounding box, and the type of car that is detected.
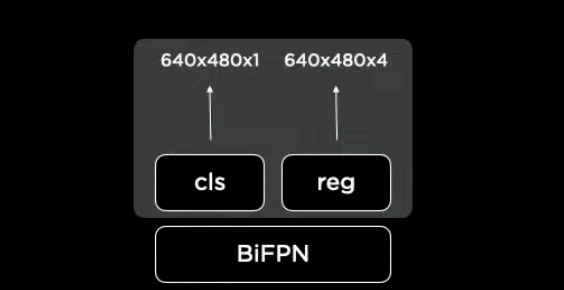
The image above depicts an output where "cls" represents the classification, "reg" denotes the regression of bounding boxes, confidence and the resolution is set to 640x480. The output resolution consists of 4 values, including the (x, y) coordinates, width, and height of the bounding box, resulting in a total of 4 outputs.
HydraNets
In Tesla FSD, there is a wide range of responsibilities, not limited to just detecting cars. Other tasks that it is designed to handle include recognizing and identifying traffic lights, predicting lanes, and other functions as well. To manage these multiple tasks, Tesla has implemented its own architectural design referred to as HydraNets. This design features a shared central structure (backbone) with various specialized offshoots (heads) that are dedicated to specific tasks.
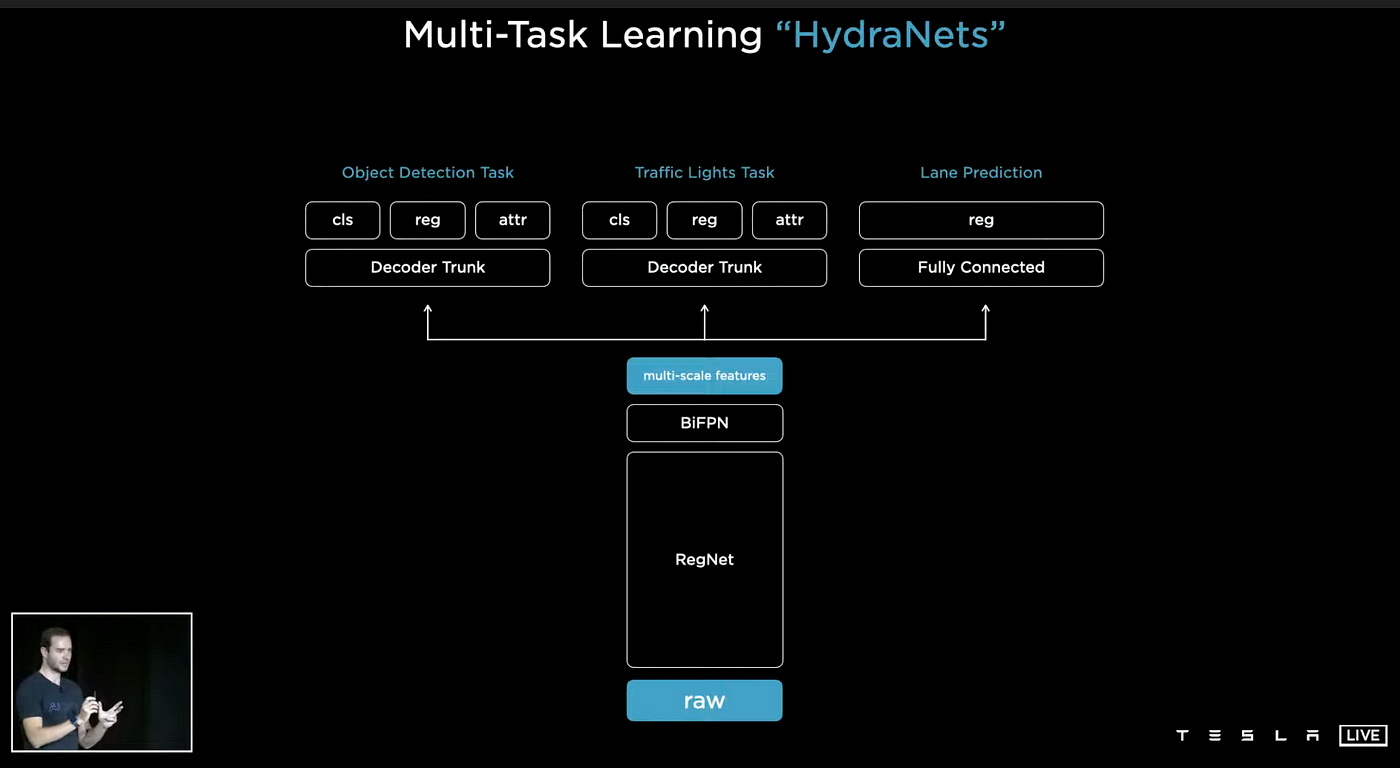
The HydraNets architecture offers several advantages, including the ability to share features among tasks, which reduces the number of convolution calculations and the number of backbones needed. This is particularly beneficial during testing. The architecture also separates individual tasks from the central backbone, allowing for fine-tuning of each task independently. Additionally, the architecture utilizes a feature caching system during training which reduces computational requirements during fine-tuning by only utilizing cached features to adjust the specialized heads.
The process for training a HydraNet model includes a combination of end-to-end training, feature caching at the multi-scale level, and fine-tuning specific tasks using the cached features. The process is then repeated with end-to-end training to achieve optimal results. The video below shows predictions from the HydraNet model.

What we've seen so far only works for simple tasks like lane-keeping in autopilot. In Part 2, we'll cover how Tesla uses input from all 8 cameras.
Part 2
Vector Space
The team at Tesla working on developing the Full Self-Driving feature (FSD) discovered that utilizing only one camera was not sufficient. To improve the system, they needed to add more cameras and convert the perception system's predictions into a 3D format, known as Vector Space. This three-dimensional representation allows for the foundation of the Planning and Control system, and it digitizes the information about the vehicle and its environment, including the vehicle's position, speed, lane, signs, traffic signals, and nearby objects, and then presents them visually in this space.

Occupancy Tracker
Tesla has created a system called the Occupancy Tracker using the programming language C++. This system stitches together curb detections from images, across camera scenes, camera boundaries, and over time. However, the design has two limitations: First, it is challenging to write the code for fusing information across cameras and for tracking, making it a difficult task to adjust the Occupancy Tracker's settings and parameters. It is also difficult for programmers to fine-tune C++ programs by hand. Second, the system does not output the results in the correct format, predictions should be made in Vector Space rather than Image Space.

As the video above shows, using per-camera detection and then fusing the results, although each camera has a good prediction individually, there is a significant loss in accuracy when they are projected into the Vector Space. (This can be seen by the red and blue lines in the projection at the bottom of the above figure). This occurs because extremely precise depth per pixel is required in order to project the images correctly. It is very difficult to predict this depth so accurately for each individual pixel. The image-space method (per-camera detection then fusion) cannot solve two scenarios: predicting occluded areas and predicting larger objects that span more than two cameras, up to five cameras. These predictions are poor, and if not handled correctly, they can even lead to dangerous traffic accidents.
Instead of using individual cameras and then fusing the results, a new approach is needed. The current method struggles with predicting depth accurately for each pixel and fails to predict occluded areas or larger objects spanning multiple cameras which could lead to dangerous accidents. A new idea should be considered where all the images are processed together by a single neural network and the output is directly in the Vector Space.
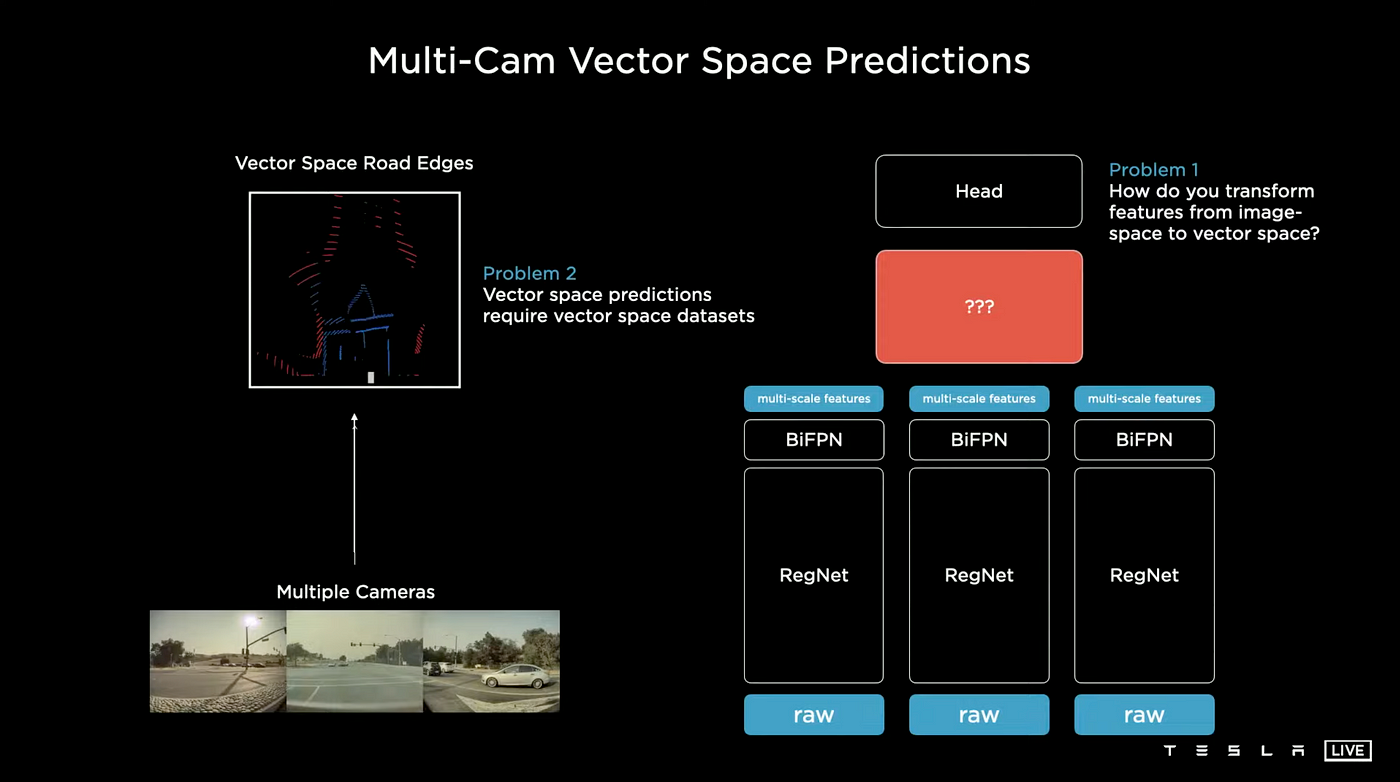
The Tesla AI team is working on designing a neural network as depicted on the right side of the above image. The network processes each image by passing it through a backbone and then transforms the image space features into vector space features before passing it to the head for decoding. There are two main challenges with this approach:
- Transforming features from image space to vector space, and
- Making the transformation process differentiable to enable end-to-end training. For deep learning algorithms to work, they must be modeled as convex optimization problems and the function being learned must be differentiable. To make vector space predictions with this neural network, it's required to use data sets specifically designed for vector space. More information about this problem will be discussed in the following article.
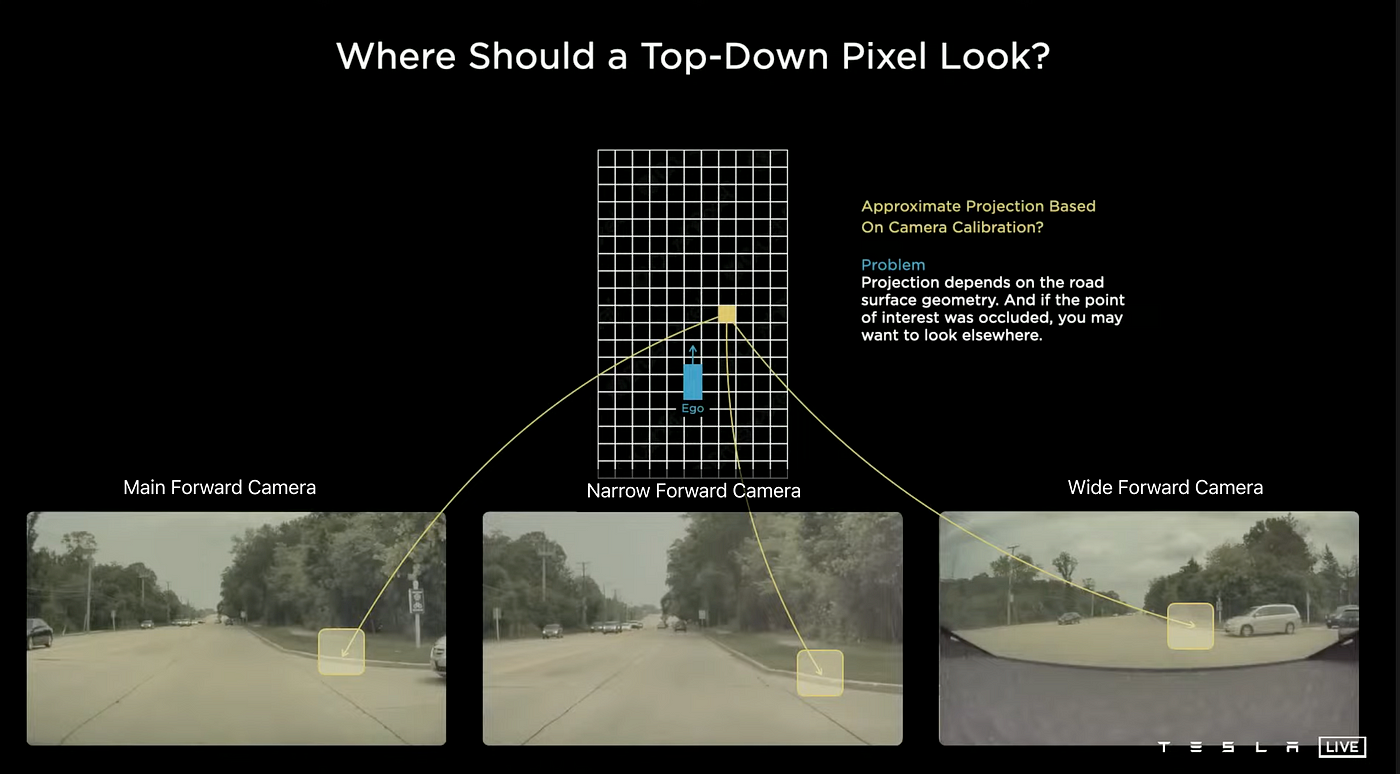
Tesla AI uses a bird's-eye-view method for predictions rather than relying on image space predictions. To illustrate, the image above shows that a single yellow pixel in the output space is derived from the projection of a road edge as detected by the three front cameras on a Tesla vehicle: the main forward camera, the narrow forward camera, and the wide forward camera. The accuracy of this projection is affected by the road surface's geometry, and if the point of interest is obscured, it may be necessary to look at other areas. It is challenging to achieve a high degree of accuracy and to establish a fixed transformation for this component. Tesla uses a transformer to increase accuracy.
Transformer
Transformer is a deep learning model that has received the most attention in recent years. It was first mentioned in the Google paper, Attention Is All You Need, and is mainly used in the field of natural language processing(NLP).
Recently, Transformer has been gaining a great deal of attention in the deep learning field. It comes from the Google paper, Attention Is All You Need, and is mainly used in natural language processing (NLP). Its core is the attention mechanism, upon which BERT, GPT, and other models are based. This attention-based approach is now commonplace in NLP, computer vision (CV), artificial intelligence (AI), and other fields.
The Transformer consists of an encoder-decoder structure. It's composed of identical layers, each of which contains a Multi-Head Attention layer and a Feed-Forward layer in the encoder and two Multi-Head Attention layers and a Feed-Forward layer in the decoder.
Attention is the ability to map a query, along with a set of keys and values, to an output, where all elements are represented as vectors. The output is computed as a weighted sum of values, with the weight assigned to each value being determined by the compatibility function between the query and the corresponding key.
There are a number of types of Attention, such as Soft Attention, Hard Attention, Self Attention, Dot-Product Attention, Single Attention, and Multi-Head Attention. In Attention Is All You Need, the Attention mechanism is composed of Multi-Head Attention with Scaled Dot-Product Attention.
Transformer is not just used in language translation. Tesla has found a way to use it to "translate" image space into vector space.
Transformer For Self-Driving
The process of training an Image-to-BEV Transformer begins with the creation of an Output Space Raster, which is of the same size as the target output. Then, each point on the Output Space Raster is Position Encoded, as are all of the images and their features, before being fed to an Encoder. This Encoder is made up of a stack of Multi-head self-attention that produces an encoded representation of the Init Vector Space raster. The target BEV is Position Encoded and fed to the Decoder, which, along with the Encoder stack’s encoded representation, produces an encoded representation of the target BEV. The Output layer then converts this into BEV features and the output Vector Space (BEV). Finally, the Transformer’s loss function compares this output sequence with the target sequence from the training data, and the gradients generated from this loss are used to train the Transformer during back-propagation.
Inference
Tesla has demonstrated the effectiveness of the process of utilizing a Transformer to transform from Image Space to Vector Space. This process can be described by the following steps: Initialize an output space raster, then positional encode the points on the raster. These points are then encoded by a Multi-Layer Perceptron (MLP) into a set of query vectors; for instance, the yellow point. Each image from the eight cameras emits its own keys and values. The keys and queries interact multiplicatively (dot-product attention in Transformer) with the Multi-Cam image feature library and the result is output to the vector space. To put it simply, the Transformer network is asked to identify features of a certain type at a particular pixel (the yellow point) in the output space (vector space). Among the eight cameras, three respond that the position is a road edge. After additional processing, the network finally outputs a road edge to that position in the Vector Space. Every pixel on the initial Vector Space Raster is processed in this way, and the transformed pixels form a complete Vector Space puzzle.
Virtual Camera
Given that the features of Tesla's 8 cameras, such as focal length, angle of view, depth of field, and installation position, differ, the same object will appear differently according to each camera, which means that this data cannot be used directly for training. Therefore, before training, we need to standardize the data from these 8 cameras into one virtual synthetic camera.
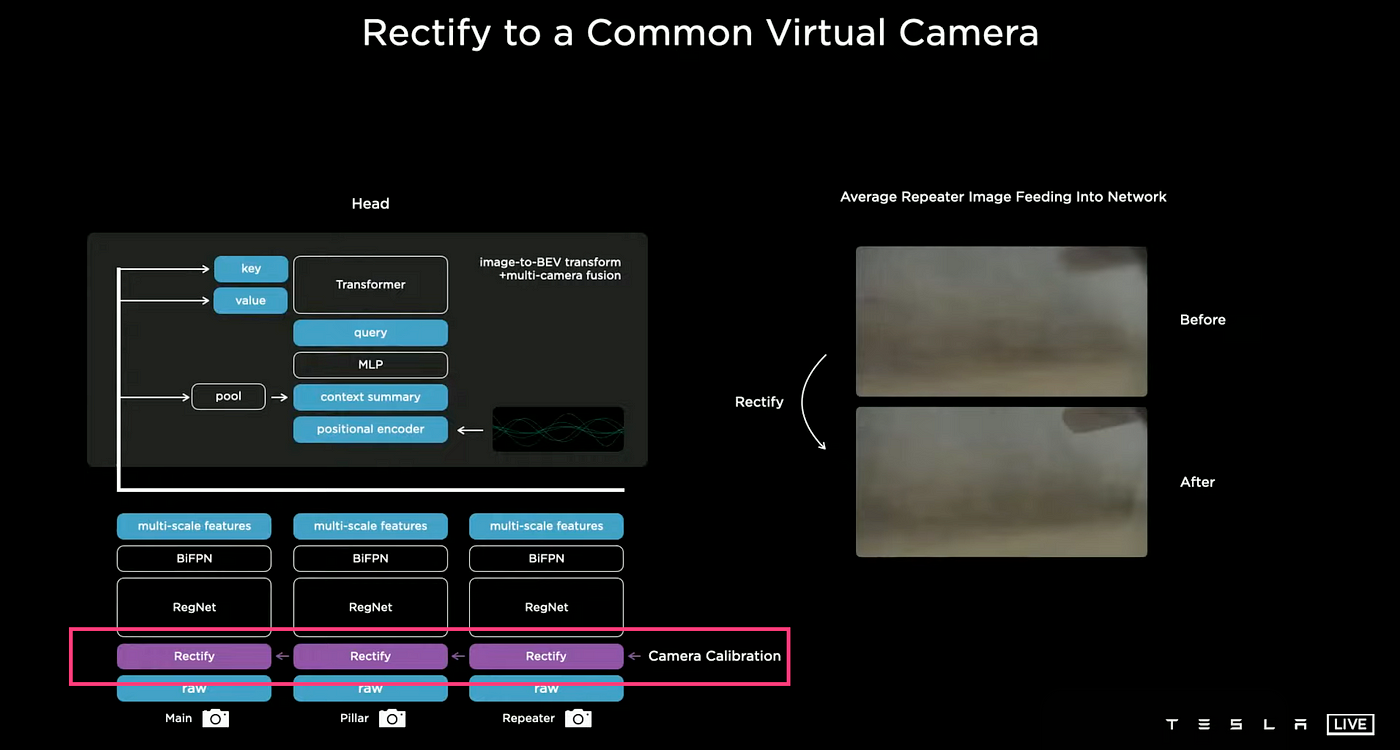
A new layer is added directly above the image rectification layer which serves the purpose of camera calibration. This layer enables the transformation of all images into a virtual common camera, thus making the previously blurred images clear and improving the performance significantly.

The image above shows the results of the neural net, which have significantly improved. The multi-camera network is capable of predicting directly in vector space and has improved object detection, even when a small portion of a car or cars crossing camera boundaries in a tight area is visible.
Video Neural Net Architecture
A Vector Space network can provide us with the necessary output for autonomous driving, but taking into account a fourth dimension – time – is essential. This time-based perspective is required to predict the behavior of objects such as cars, determine their speed, identify whether they are parked or moving, and even remember the driving context in some cases.
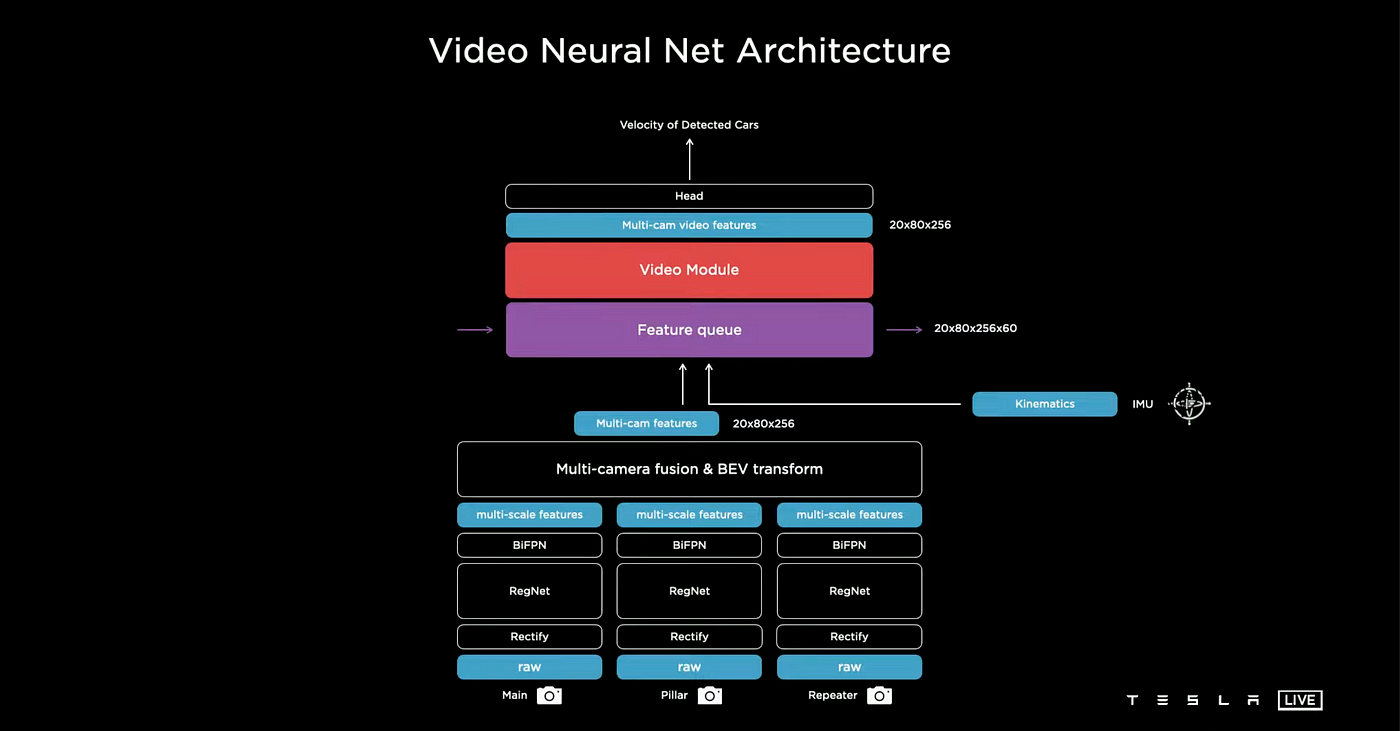
The Tesla AI team is attempting to incorporate two components into the neural network setup: a feature queue module for caching certain features over a certain period and a video module for integrating this information over time. They are also supplying the network with kinematics, or velocity and acceleration from an Inertial Measurement Unit (IMU), alongside the data from eight cameras. This particular version of Tesla AI only takes input from eight cameras and IMU.
Feature Queue
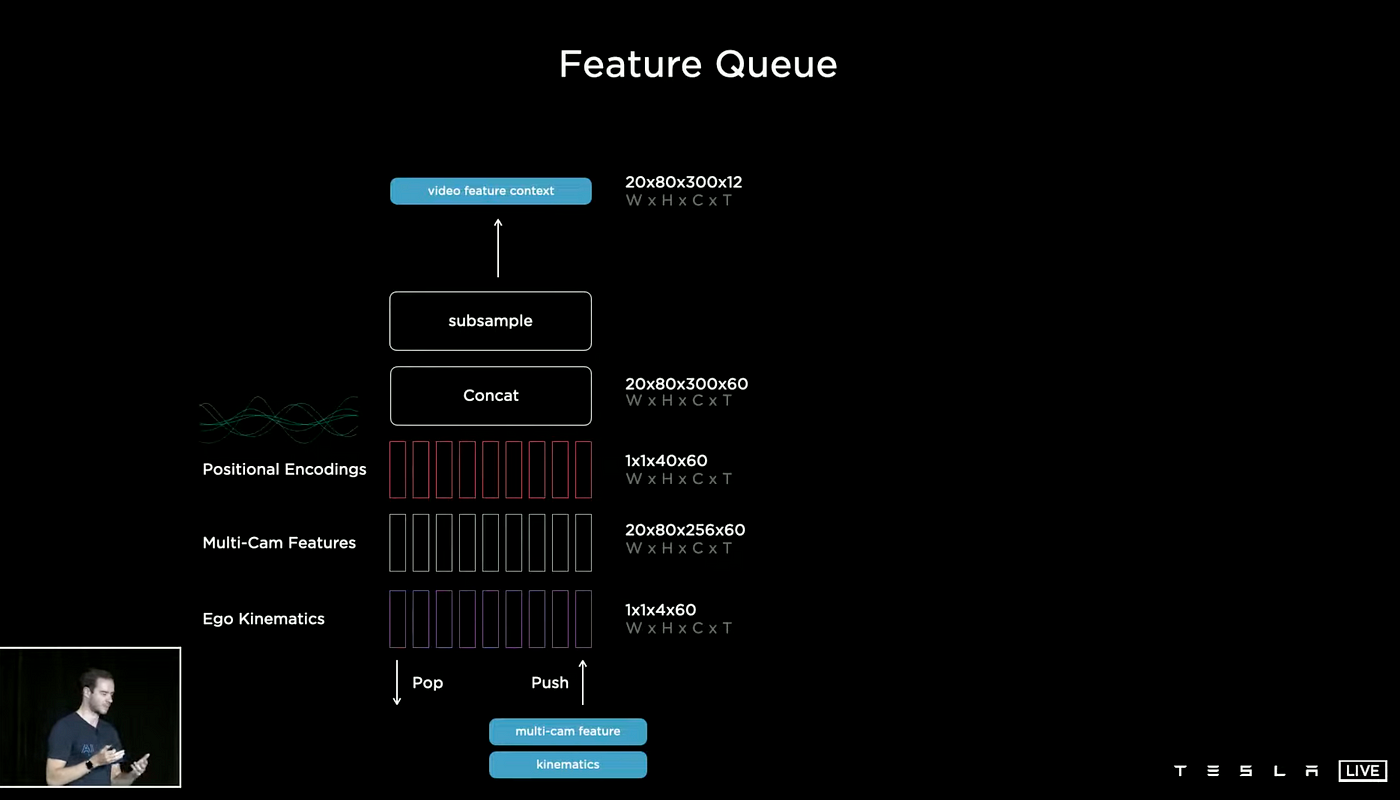
The layout of the Feature Queue is illustrated above, with three queues - Ego Kinematics, Multi-Cam Features, and Positional Encodings - being combined, encoded, and stored. This queue is then consumed by the video. This data structure functions as a First-In-First-Out (FIFO) queue with pop and push mechanisms that are essential to the Tesla AI case. Two types of push mechanisms can be used for the queue: Time-Based Queue which stores information on a time series, and Space-Based Queue which stores information on a space.
Time-Based Queue
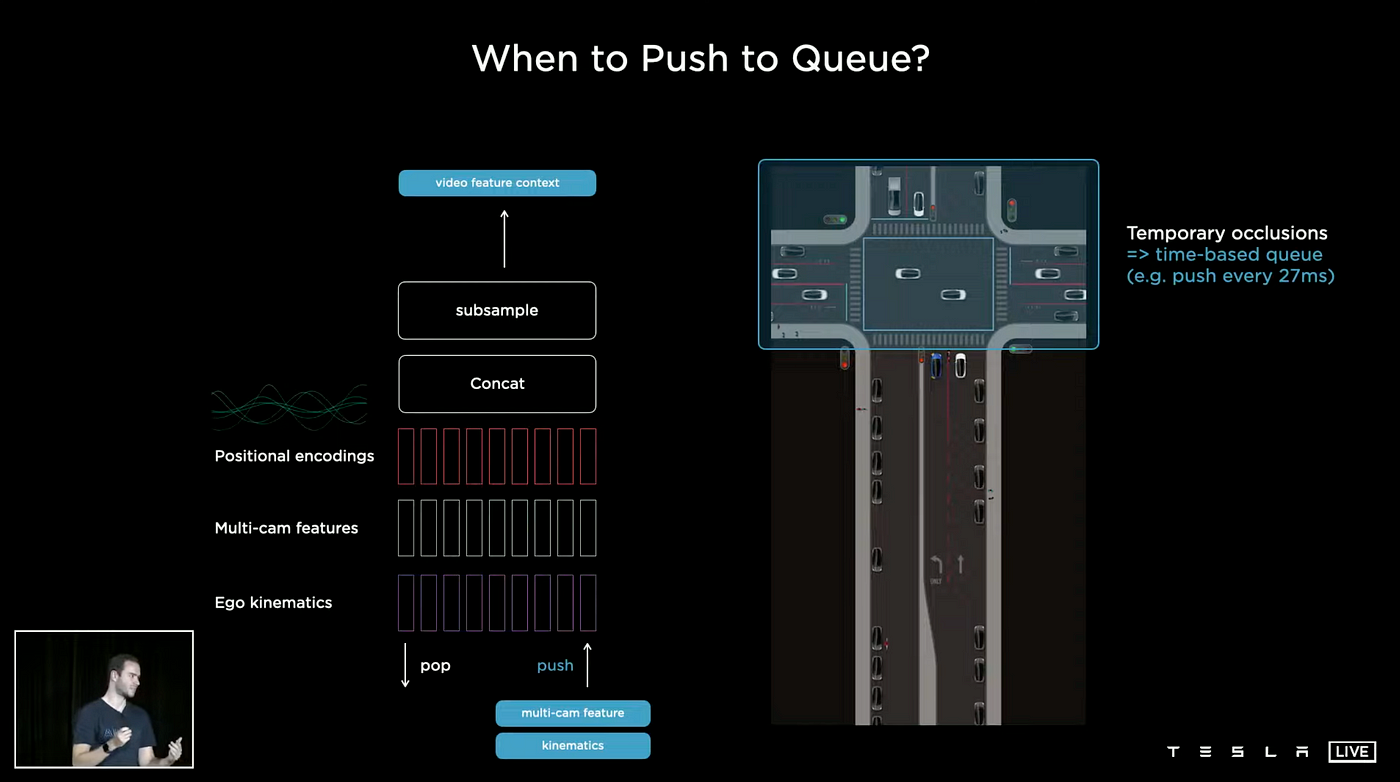
In the above image, cars are seen approaching the intersection. As other vehicles advance, they can temporarily obstruct the vehicles in front. This will cause those cars to stop and wait their turn. To solve this problem, a Time-Based Queue can be used, where features are placed into the queue every 27 milliseconds. This is based on the Tesla camera parameter of 1280x960@36Hz, where each frame has an interval of 0.0277 seconds or 27 milliseconds. The neural network has the ability to look back and reference past memories, so even if a car is partially blocked, a detection can still be made.
Space-Based Queue
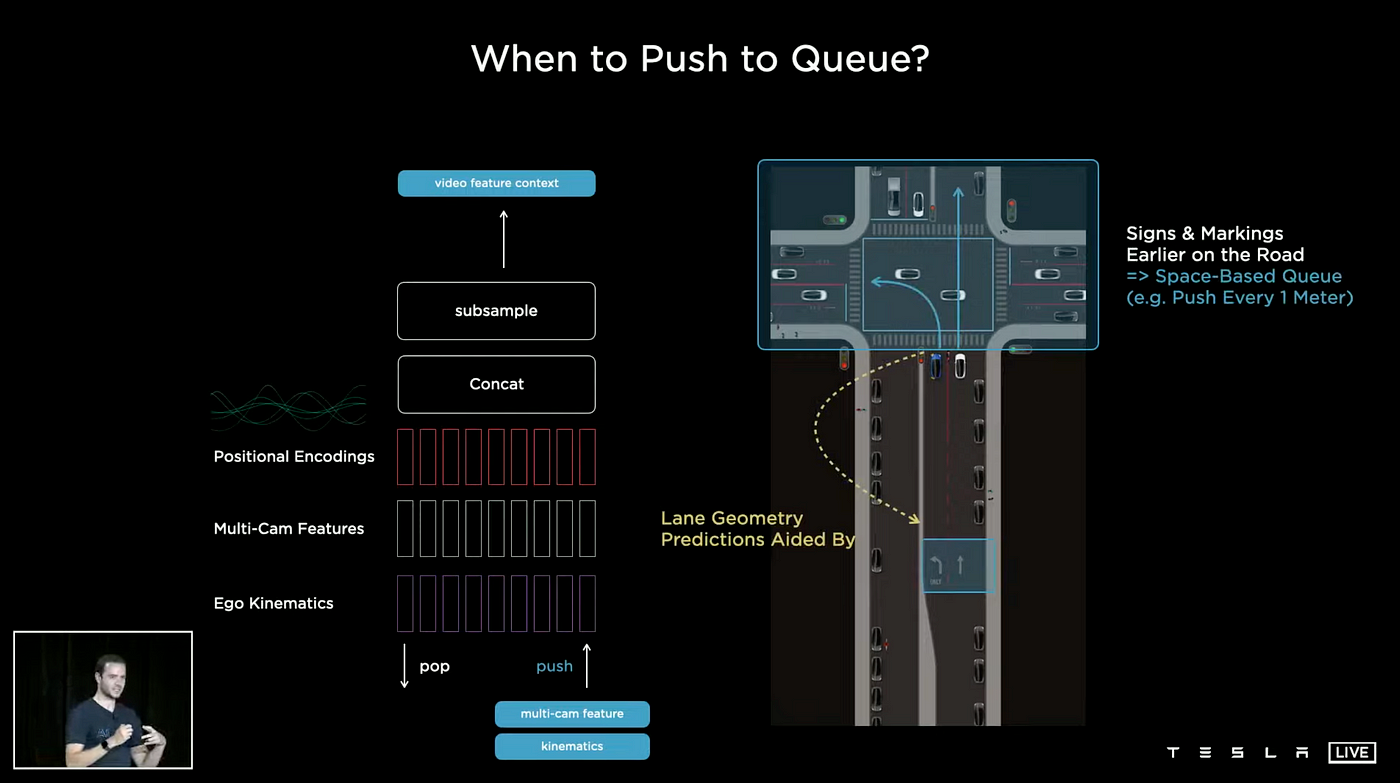
The Time-Based Queue stores feature information while a car is waiting at a red light, while the Space-Based Queue logs feature information every time the car moves forward a fixed distance. This allows the Tesla AI to predict what lane the car is in and what lane the car next to it is in.
Video Module
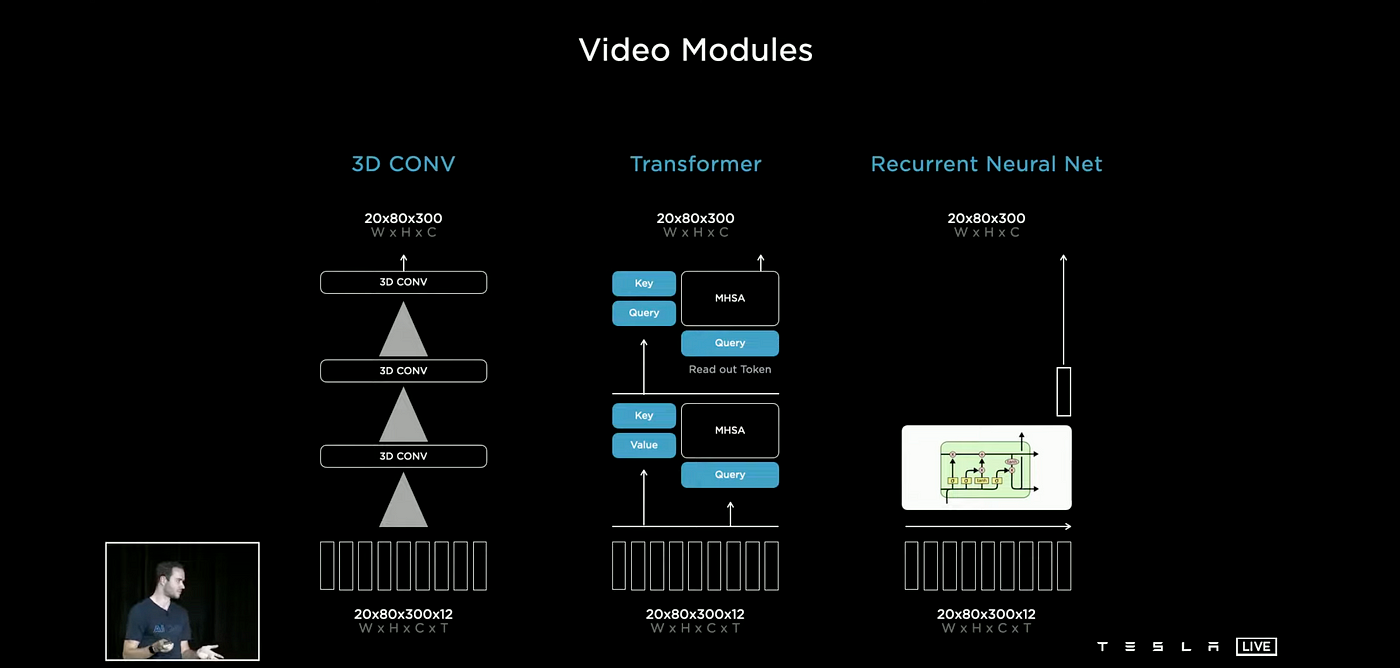
When it comes to the video module, there are a variety of options for fusing temporal information, such as 3D-Convolutions, Transformers, Axial Transformers, Recurrent Neural Networks, and Spatial RNNs. Of these, the Tesla AI group has a particular fondness for Spatial Recurrent Neural Networks.
Recurrent Neural Network
To understand Spatial Recurrent Neural Networks, we need to understand Recurrent Neural Networks (RNN), Long short-term memory (LSTM), and Gated Recurrent Unit (GRU). RNNs are a type of artificial neural network employed for dealing with sequential data, commonly used in natural language processing (NLP). RNNs are composed of a loop structure that grants them memory. Although RNNs are capable of remembering data, they possess limited short-term memory and are not able to store "long-distance" information. This is due to the increased use of RNNs units, resulting in a vanishing gradient problem that impedes the attainment of long-term memory. Gated Recurrent Units (GRUs) were developed as a modification to the RNN hidden layer, allowing for the capturing of long-range connections and mitigating the vanishing gradient issue. The other type of unit that allows for the combination of both long-term and short-term memory is the Long short-term memory (LSTM), which is more powerful than the GRU. GRUs and LSTMs are variants of RNNs and share the same Gates mechanism, with GRUs being seen as a simplified version of LSTM.
Spatial Recurrent Neural Network
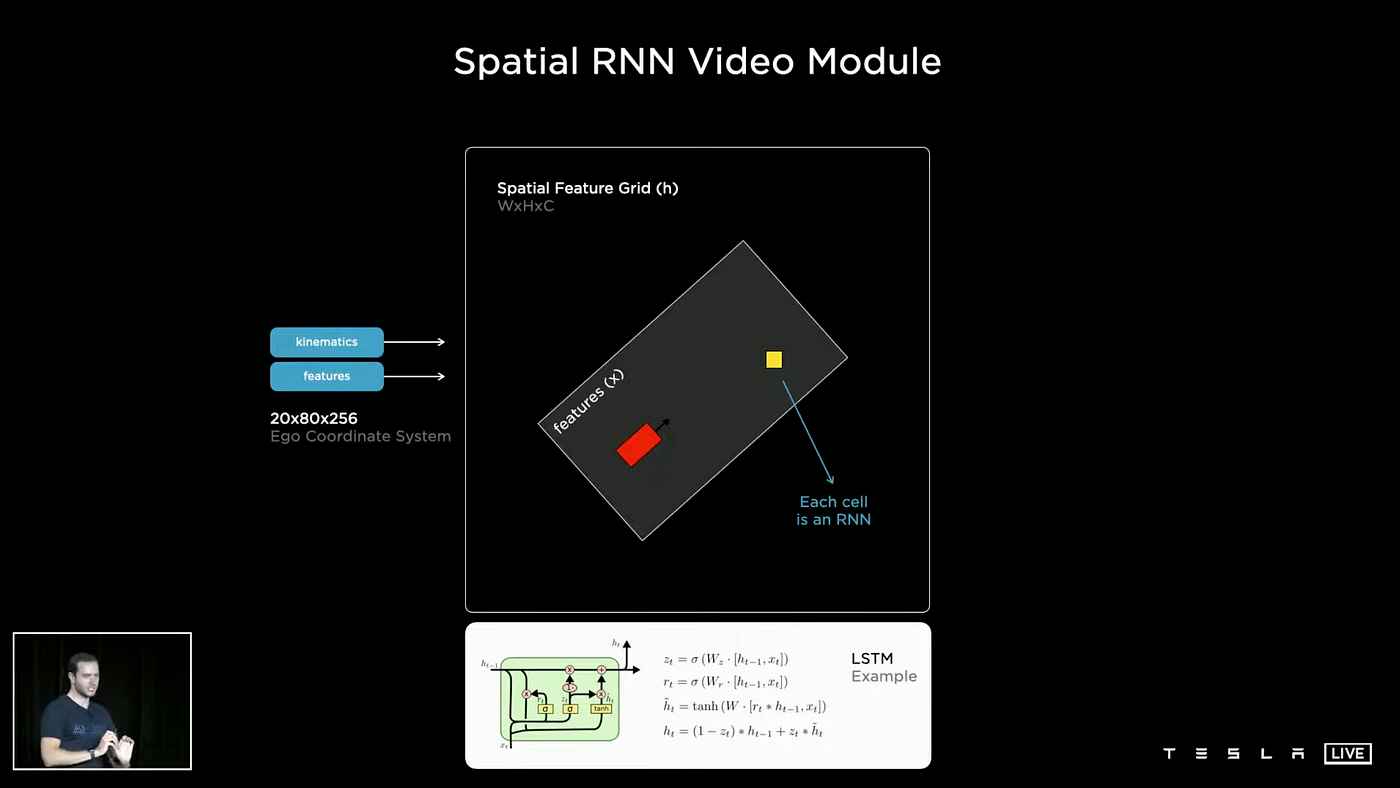
In order for the network to possess a long-term memory, the use of Recurrent Neural Networks (RNNs) is necessary. From the image above, we can observe that Spatial RNN has a GRU unit structure. GRU has a more modest number of parameters and faster convergence speed, making it more efficient for the limited computing capabilities of the onboard chip. As a result, the Tesla AI team has opted for the simpler GRU instead of LSTM or other complex structures.
In particular, for the Tesla self-driving mechanism, the two-dimensional surface is being navigated. The Tesla AI team has thus arranged the hidden states in a two-dimensional lattice. When the car is being driven, the network only updates the parts close to the car and in the car's line of sight. Kinematics is used to integrate the car's position in the hidden features grid, with the RNN only being updated at points close by.
Every lattice has an RNN network and the red rectangle symbolizes the ego car, while the white rectangle denotes the features which are in a certain range around the ego car. As the ego car travels from A to B, the feature box also moves. At this stage, we only need to modify the RNNs in the yellow boxes that are covered by the feature box. Spatial RNN has been proven to be highly efficient, as you can see in the video below.
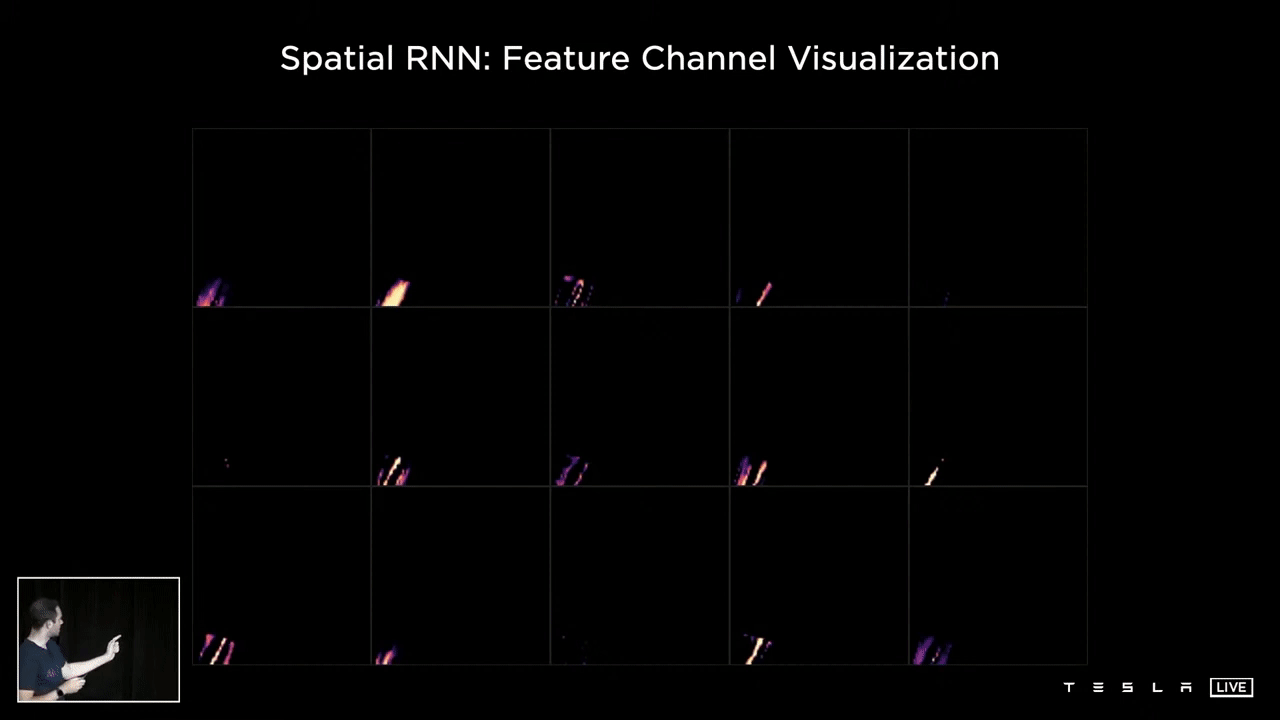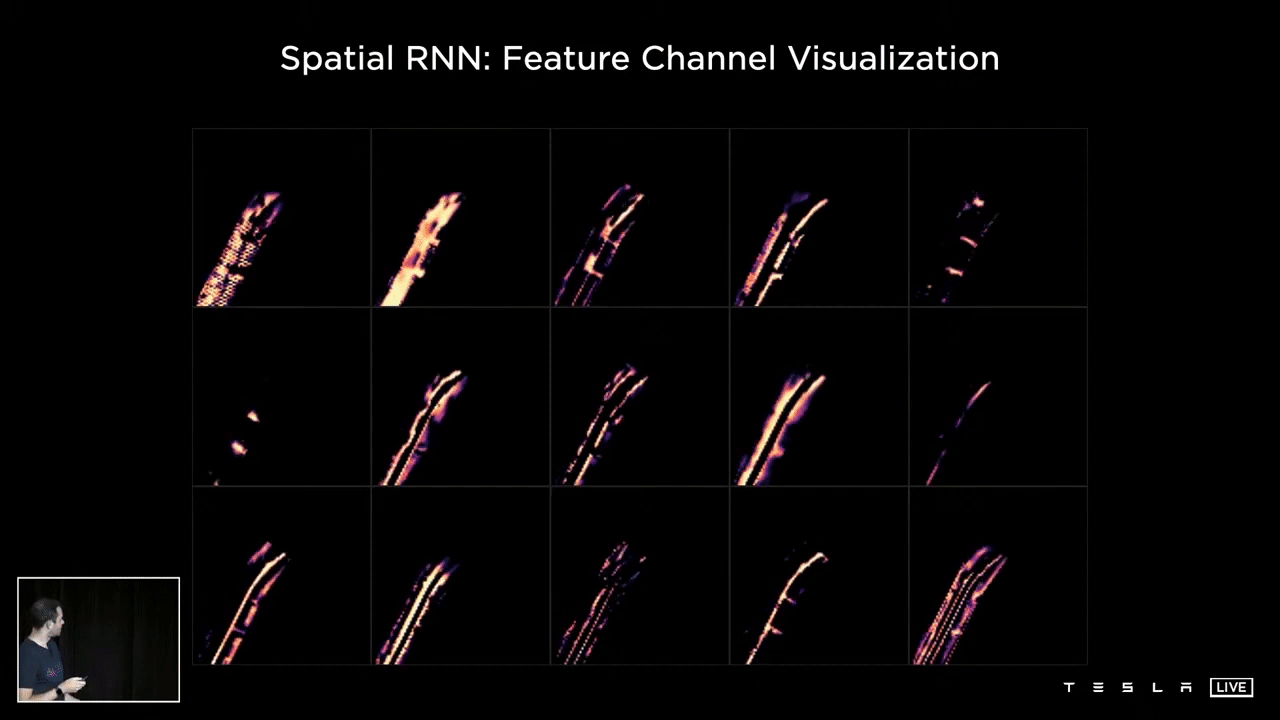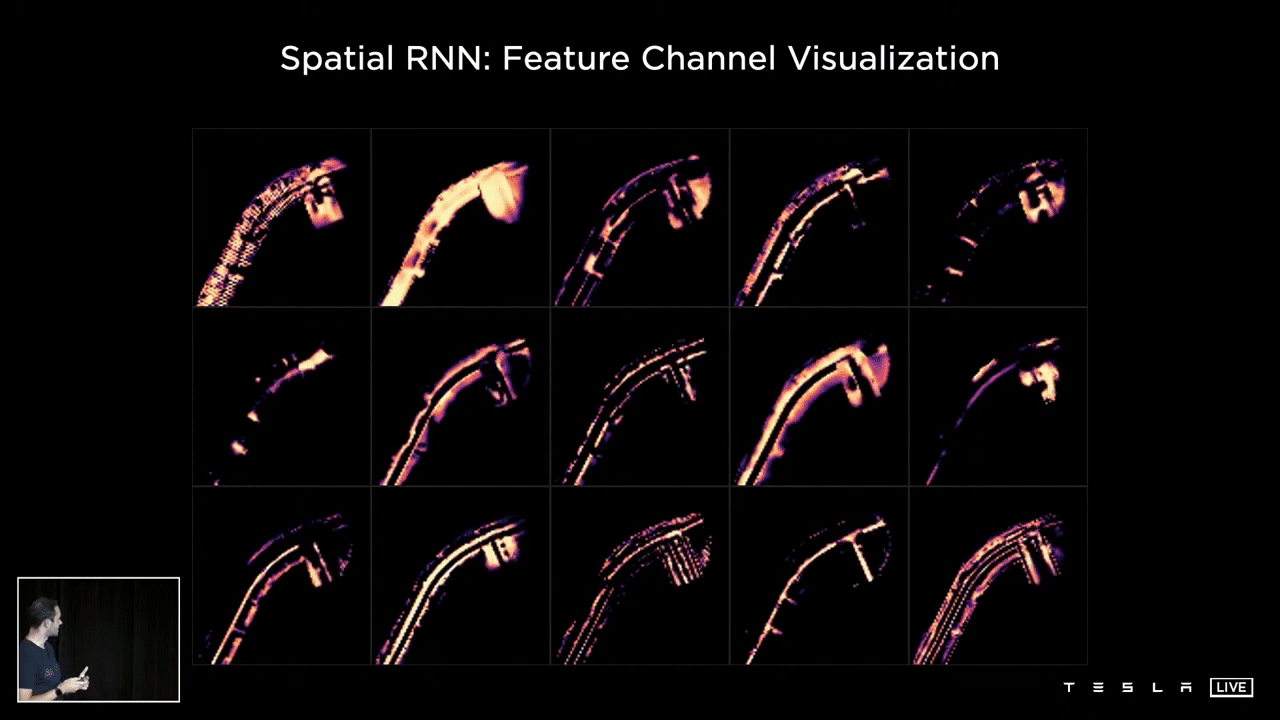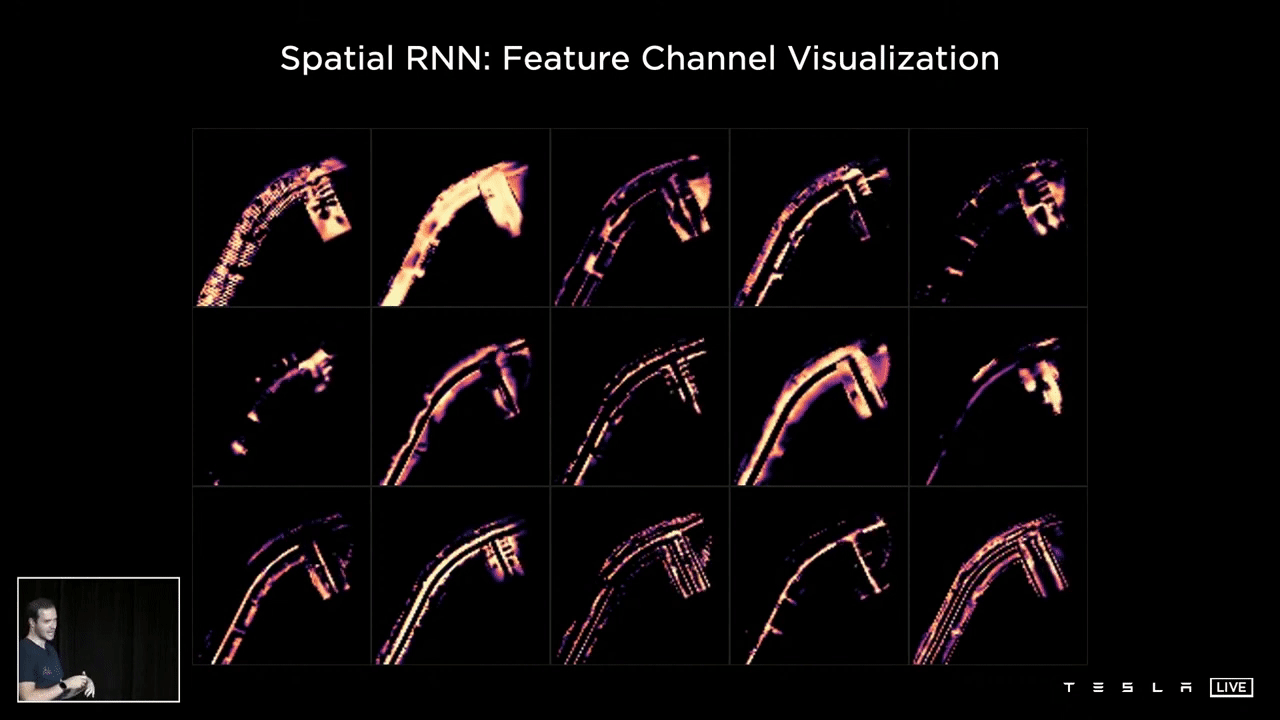
The following visualization showcases various channels within the hidden state of a Spatial RNN. Observing the 15 channels, one can discern a variety of features such as the center of the road, the edges, the lines, and the road surface. This representation illustrates what the hidden state of the RNN looks like following optimization and training of the neural network. It is clear that certain channels are specifically tracking different characteristics of the road, such as its center, edges, lines, and surface.
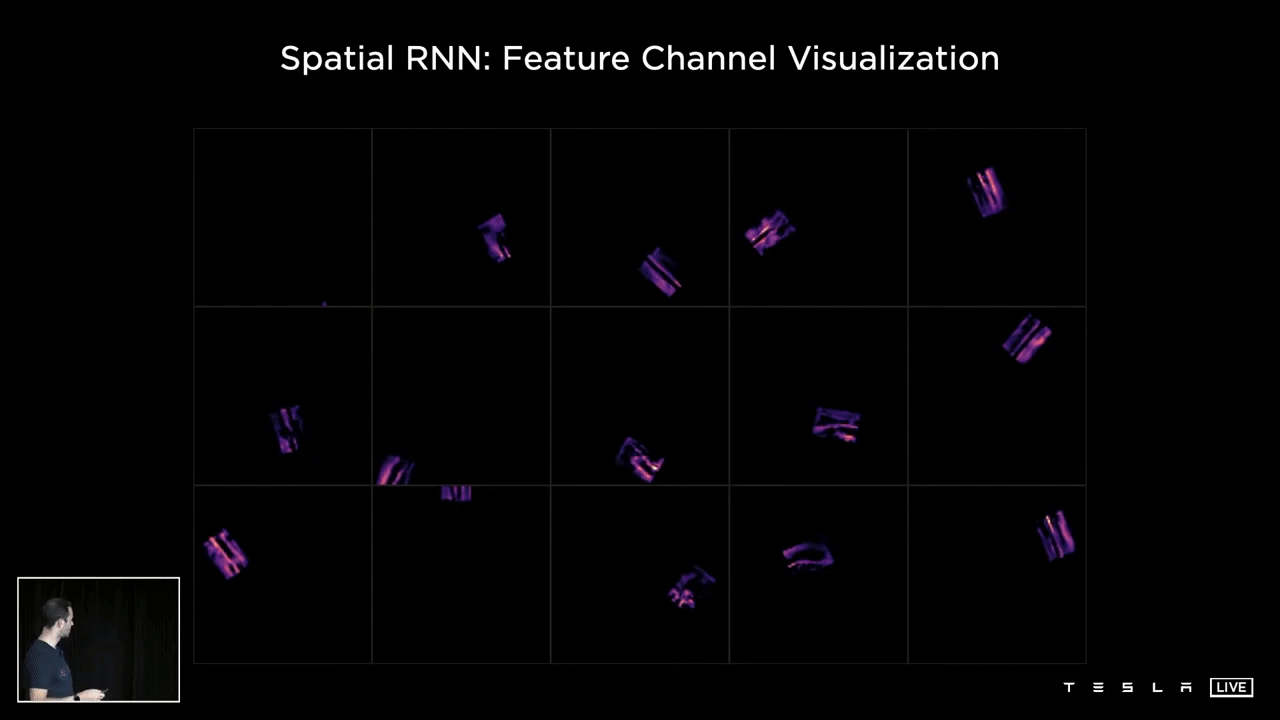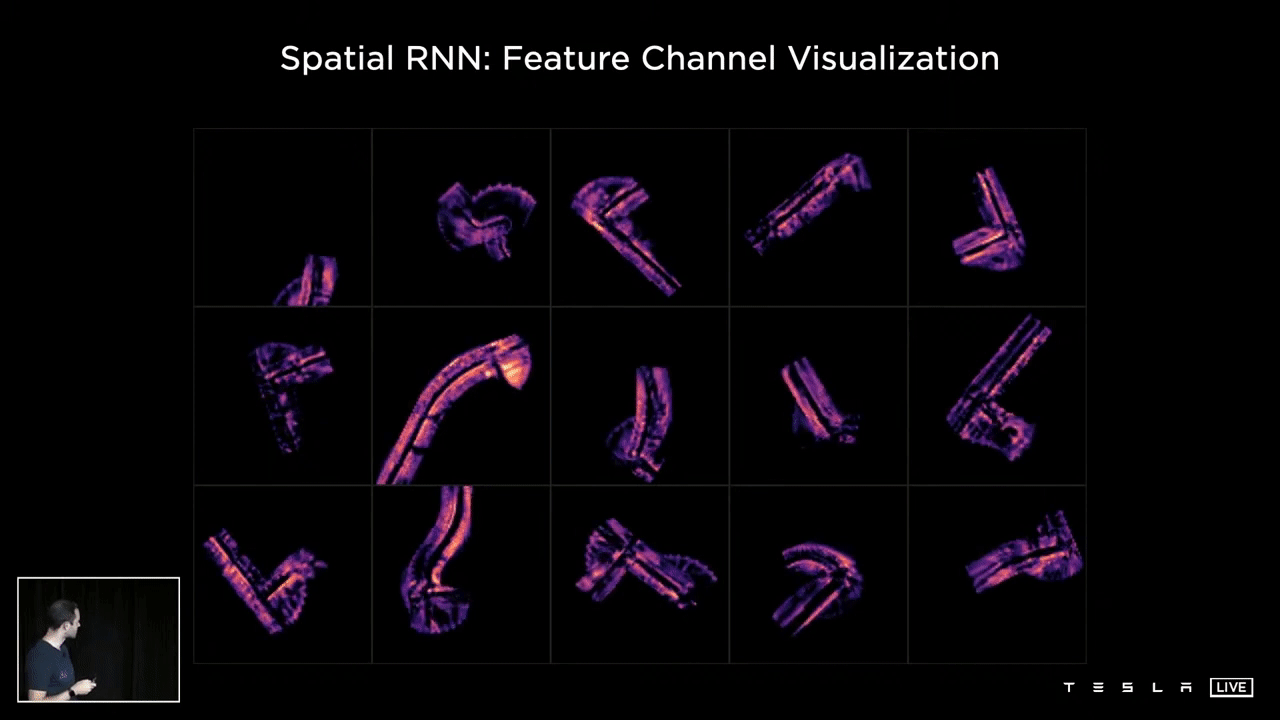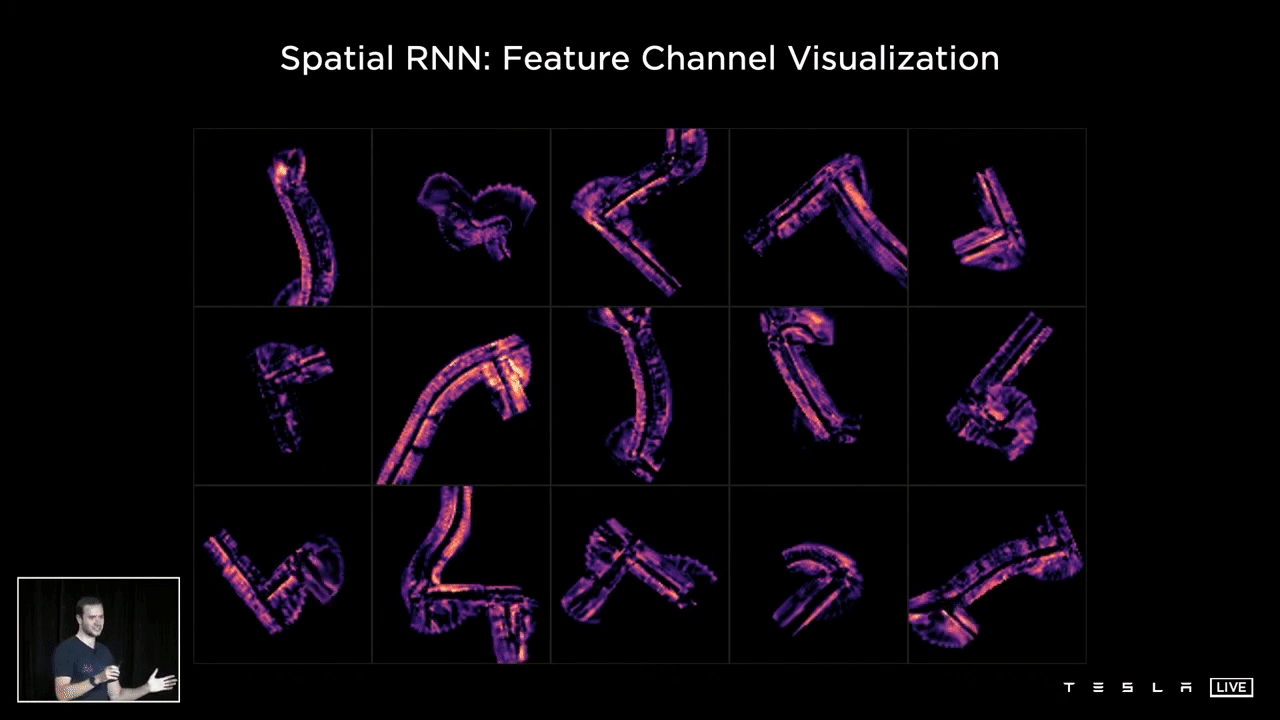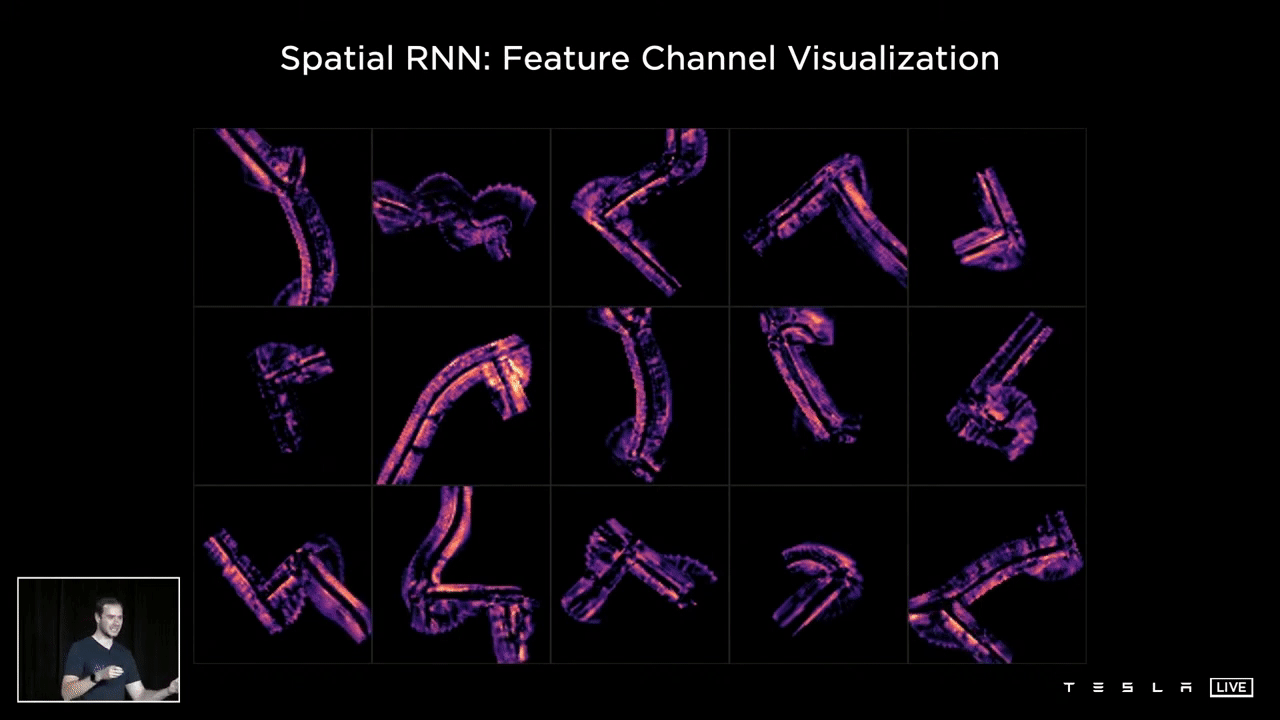
This example illustrates the average of the first 10 channels within the hidden state for different intersection traversals. The RNN is able to continuously monitor the current situation, and the neural network has the capacity to selectively read and write to this memory. For instance, when a car is present next to the vehicle and obstructing certain portions of the road, the network can choose not to record information in those areas. Conversely, when the car moves away and the view improves, the RNN can choose to document information about that section of the space. The result is a comprehensive understanding of the driving scenario, with no missing information due to temporary occlusions, leading to accurate operation.

The following visualization presents a few predictions from a single clip using a Spatial RNN. However, this process can be repeated multiple times, using a variety of clips from multiple cars to construct an HD map. This map will be utilized in later stages of the Auto Labeling process.
The Spatial RNN offers several benefits, including:
- Improved Robustness to Temporary Occlusion: As demonstrated in the example, when two cars pass by and briefly obstruct one another, the single frame network loses detection, while the video module is able to retain the memory. Furthermore, when the cars are only partially obscured, the single frame network produces a poor prediction.
- Improved Depth and Velocity From Video Architecture: The Spatial RNN demonstrates significant improvements in its ability to estimate depth and velocity, as seen in the comparison between the radar depth and velocity in green, single frame performance in orange, and video modules performance in blue. Additionally, Tesla started deliveries of Model 3 and Model Y vehicles built for the North American market without radar equipped.
Tesla Vision Structure
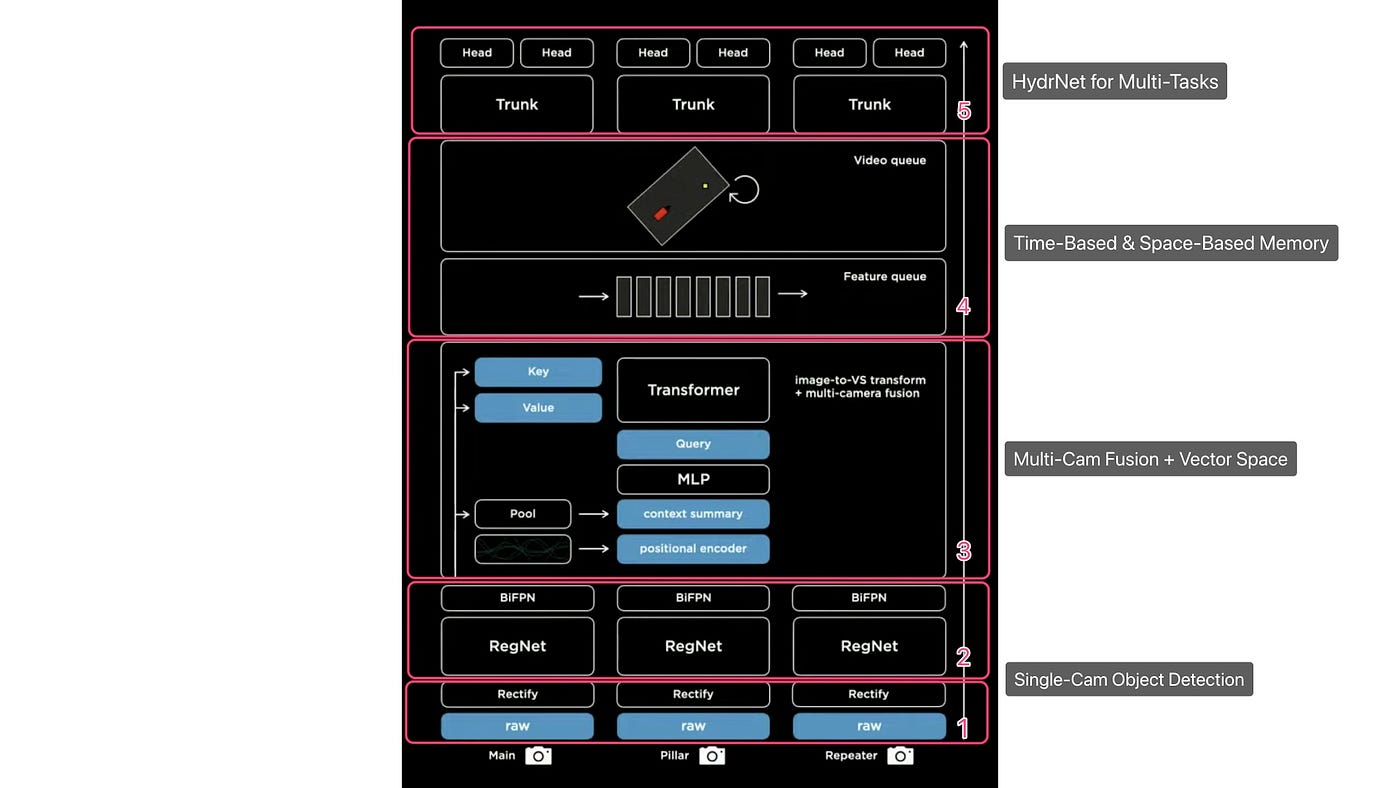
The raw images are inputted at the bottom and go through a rectification layer to adjust for camera calibration and align everything with a common virtual camera. They are then processed by RegNets residual networks, which extracts a number of features at different scales and combines the multi-scale information using BiFBN. The image representation then goes through a transformer module to be converted into a vector space, and output space. This is followed by being fed into a featured queue in time or space, which is then processed by a video module such as a Spatial RNN. The processed images then go through the branching structure of the HydraNet, which includes trunks and heads for various tasks. At present, most electric vehicle manufacturers’ vision systems are still in the early stages of this architecture process, only implementing the first and second steps.
Part 3
Planning and Control
The vision network utilizes dense video data, compressing it into a 3D Vector Space representation. The planner's role then is to utilize this Vector Space and guide the vehicle to its destination while also prioritizing safety, comfort, and efficiency. As an experienced human driver with over ten years of experience, I believe that achieving a balance between these three elements is crucial for successful driving.
The early version of Tesla Autopilot, prior to being rebranded as Full Self-Driving (FSD), already demonstrated strong performance on highway driving scenes. It was able to maintain lanes, make necessary lane changes, and take exits off the highway. However, the FSD system aims to extend this level of performance to city street driving as well, which is a more complex task.
City driving poses a number of challenges, particularly with regard to the Action Space, which is a non-convex and high-dimensional problem. This requires the planner to be able to navigate through multiple options and make real-time decisions in a dynamic and complex environment.
Non-Convex
When a problem is non-convex, it means that there are multiple solutions that may be satisfactory, however, it can be challenging to identify a solution that is globally consistent. This is because there may be multiple local minima that the planning algorithm can become stuck in.
High-Dimensional
The complexity of the car's motion planning arises due to the need to predict the position, velocity, and acceleration of the vehicle over a time period of 10 to 15 seconds. This generates a large number of parameters to be considered in real-time. To handle this complexity, two common methods are typically employed: discrete search and continuous function optimization. Discrete search methods are effective for tackling non-convex problems as they do not get trapped in local minima. However, they are not well suited for high-dimensional problems as they do not utilize gradient information and instead must explore each point individually, making them inefficient.
On the other hand, continuous function optimization excels at handling high-dimensional problems by using gradient-based methods to quickly converge on a solution. However, when faced with non-convex problems, these methods can become stuck in local minima and produce suboptimal solutions. The Tesla AI team has developed a hierarchical approach to address this issue, first using a coarse search method to simplify the non-convexity and create a convex corridor, and then utilizing continuous optimization techniques to generate a smooth final trajectory. Two examples of the processing of the Tesla Hybrid Planning System are shown in the following scenarios.
Lane Changes
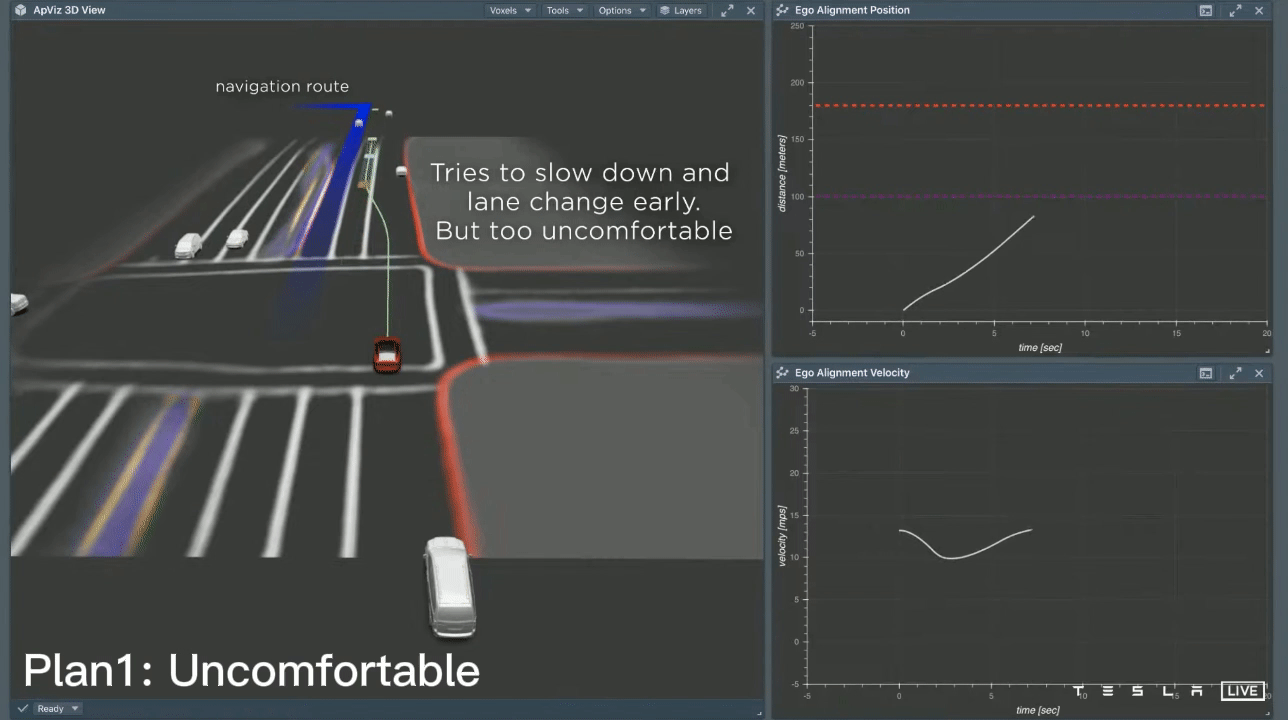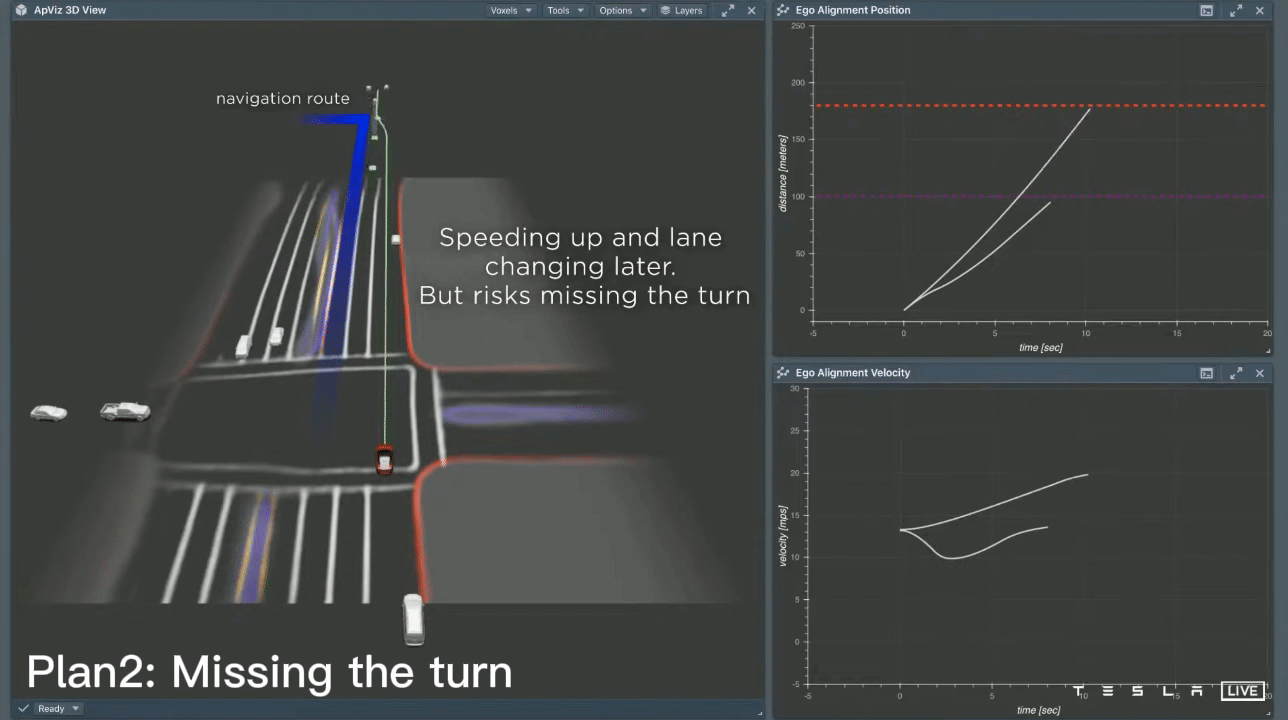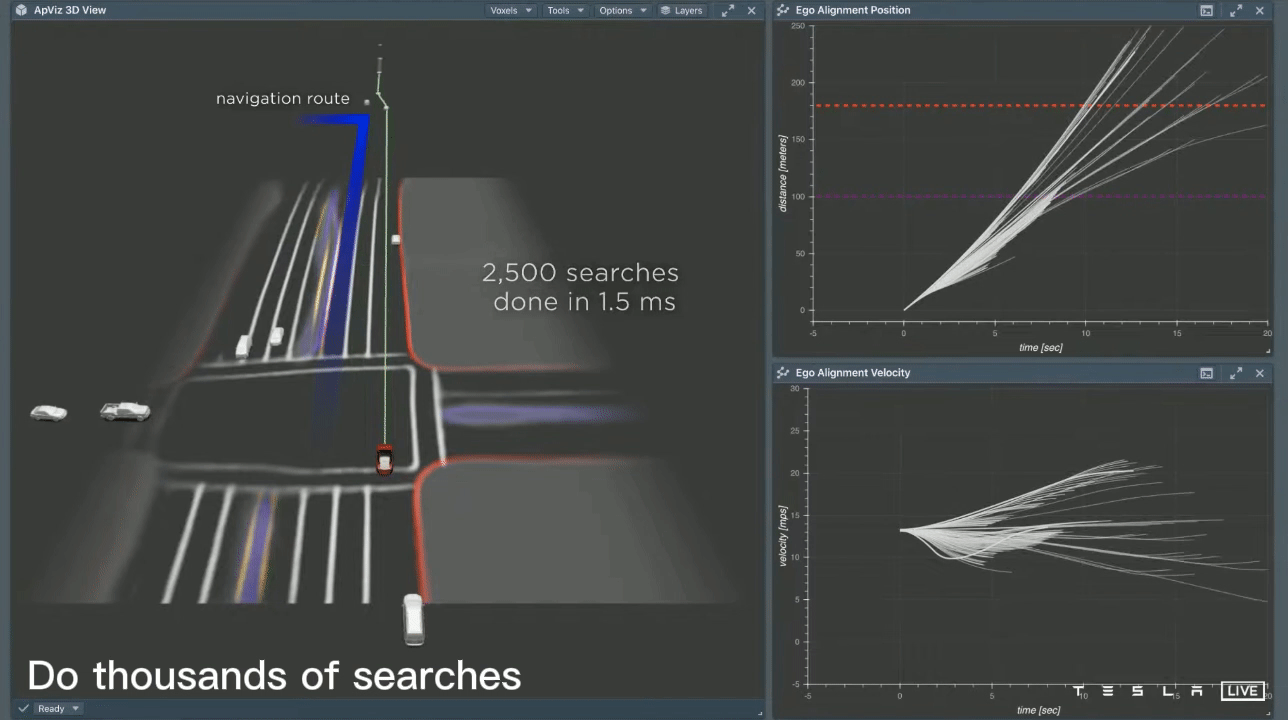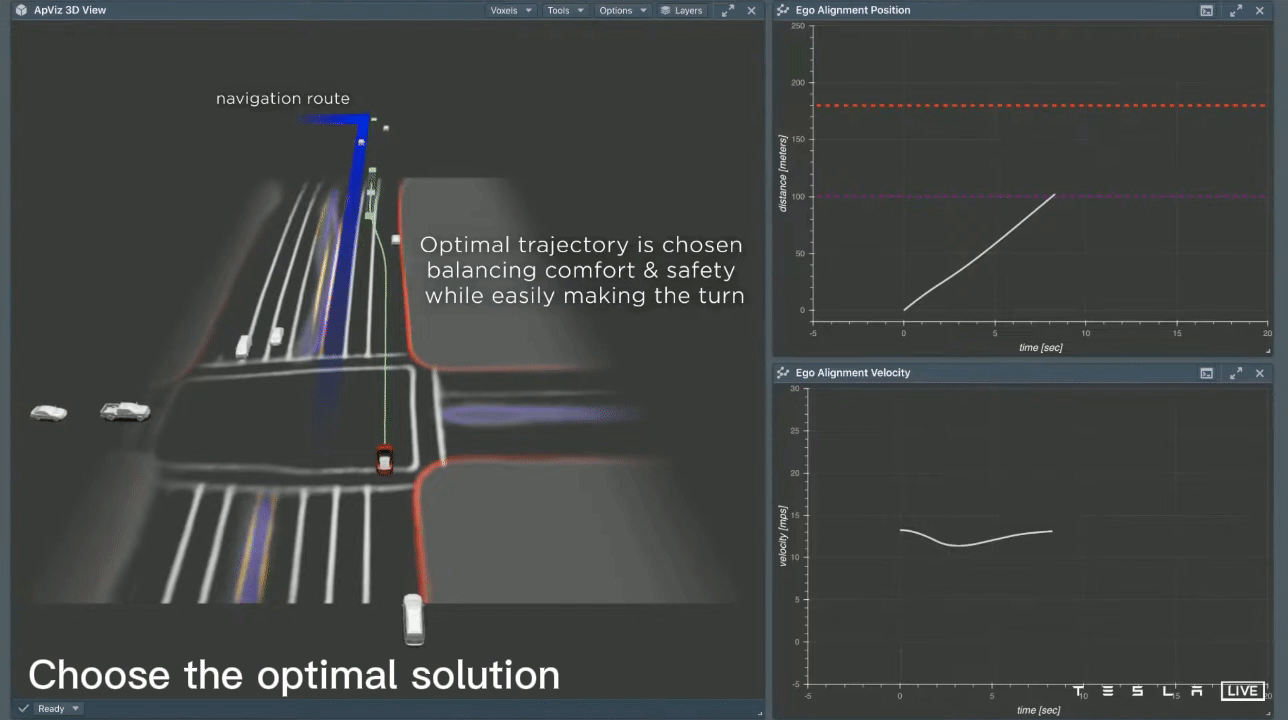
In this scenario, the vehicle needs to perform two consecutive lane changes in order to make a left turn up ahead. Initially, it considers a lane change that is close by, but this results in a harsh braking experience for the passengers. The second option the vehicle considers is a lane change that is executed later, resulting in the vehicle accelerating and passing behind and in front of other cars. While this may be a viable lane change option, it risks missing the left turn. To arrive at a final decision, the planner repeatedly considers thousands of different possibilities in a very short period of time. Specifically, it performs 2500 searches in just 1.5ms. This search speed is incredibly fast; at a speed of 60km/h, 1.5ms corresponds to only 2.5cm of distance traveled. Ultimately, the planner selects the best option based on a balance of safety, comfort, and the ability to make the turn smoothly.
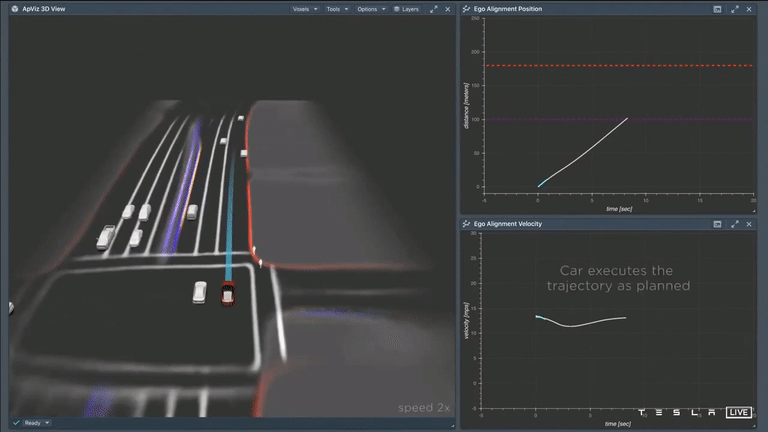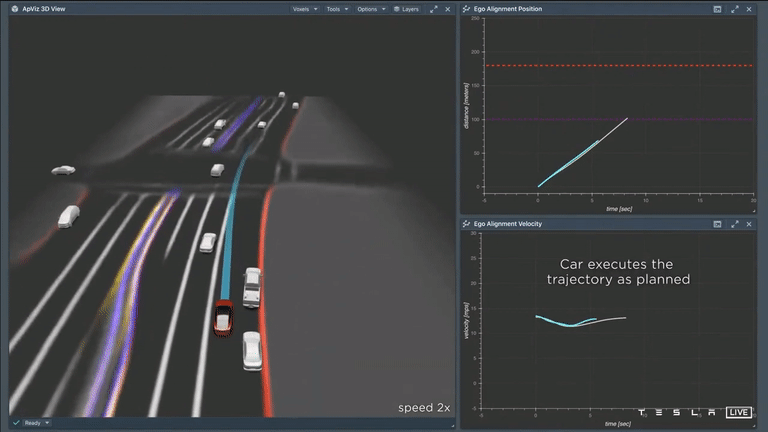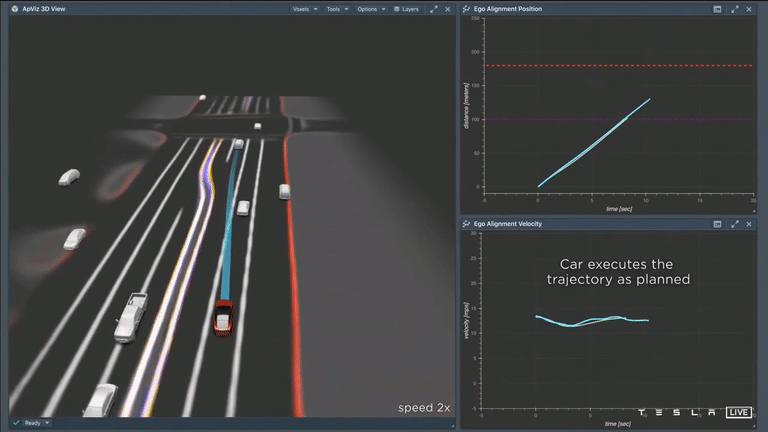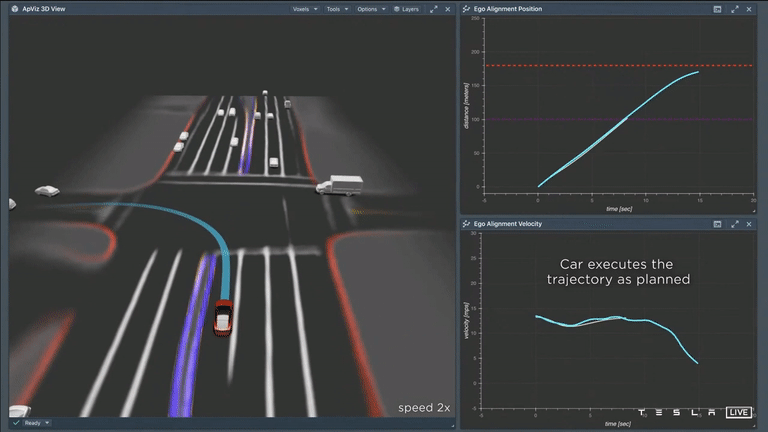
After carefully considering all available options, the car has now selected a specific trajectory. It can be seen that as the car follows this path, it closely aligns with the initial plan. The image shows the actual velocity of the car (in cyan) on the right, with the original plan (in white) depicted underneath. This indicates that the car's plan was able to accurately predict the vehicle's movements over a time period of 10 seconds. It is a well-crafted plan and it is clear that the Tesla AI system is able to effectively anticipate the car's actions over the next 10 seconds.
Narrow Roads
When navigating a city's narrow streets, it is crucial to not only plan for our own car's movement but also to take into account the actions of all other vehicles and optimize for the overall flow of traffic. To accomplish this, the Tesla AI team runs the autopilot planner on all relevant objects within the environment.

As demonstrated in the above scenario, when driving on a narrow road, it's essential for the Autopilot system to not only consider its own actions, but also the actions of other vehicles in order to optimize for overall traffic flow. In this example, oncoming car #1 arrives first, and Autopilot slows down slightly but quickly realizes that there is not enough space on its side to actively avoid the oncoming car. Instead, it determines that the other car will likely yield to the Autopilot vehicle, and so it assertively proceeds. A second oncoming car #2 then arrives with a higher velocity. In this situation, the Tesla AI team runs the autopilot planner for this other vehicle. The prediction results show that there is a high probability that the oncoming car will go around other parked cars (red path), but a low probability that they will yield (green path). Based on these predictions, Autopilot decides to pull over. However, as the Autopilot is pulling over, it observes that the oncoming car is actually yielding based on its yaw rate and acceleration, and so the Autopilot immediately changes its decision and continues to make progress. Because it is impossible to know the exact actions of other participants in the scene, the Autopilot system must plan for every object and ultimately optimize for a safe, smooth, and fast path within the corridor.
Parking Problem
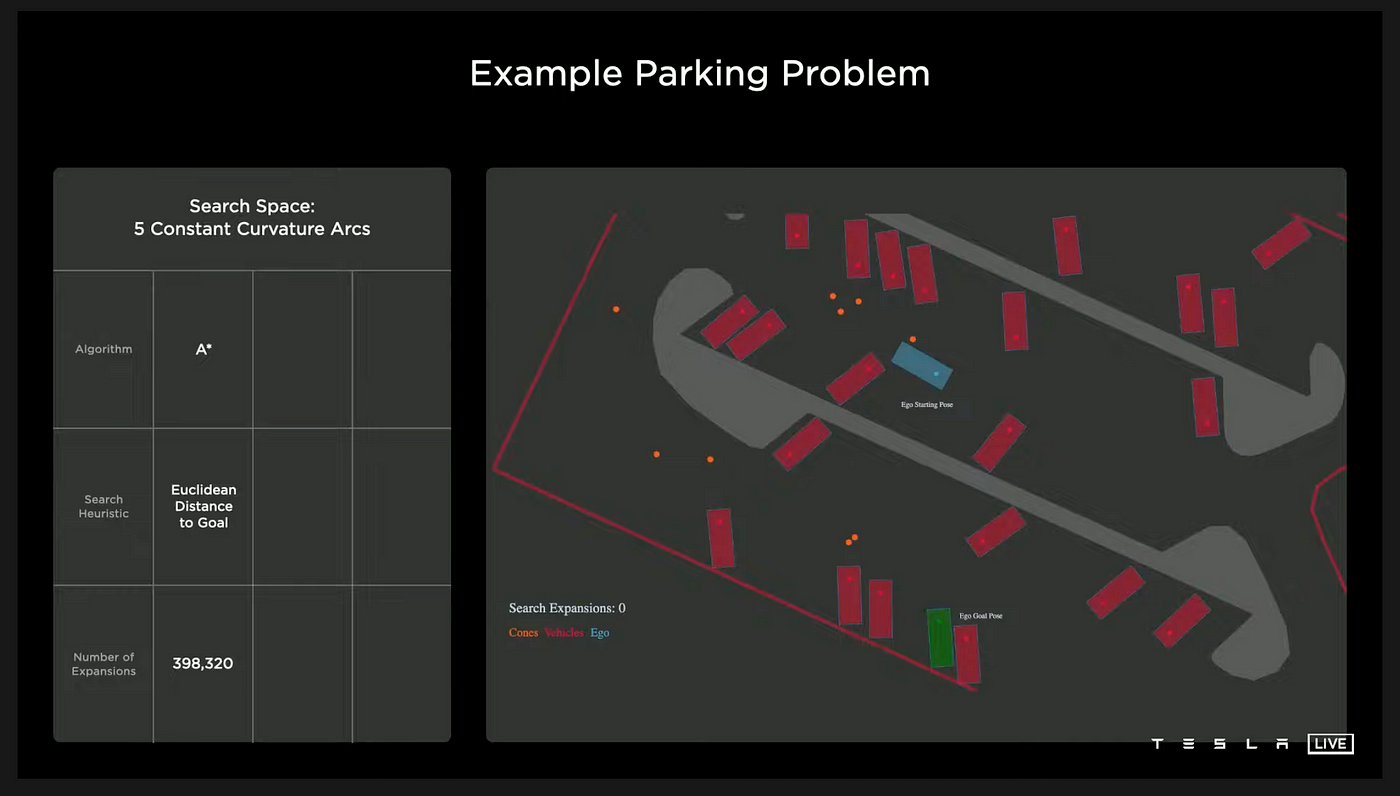
The objective is for the car (depicted in blue) to successfully navigate to and park in the designated green parking spot while avoiding obstacles such as curbs, parked cars, and orange cones.
Baseline
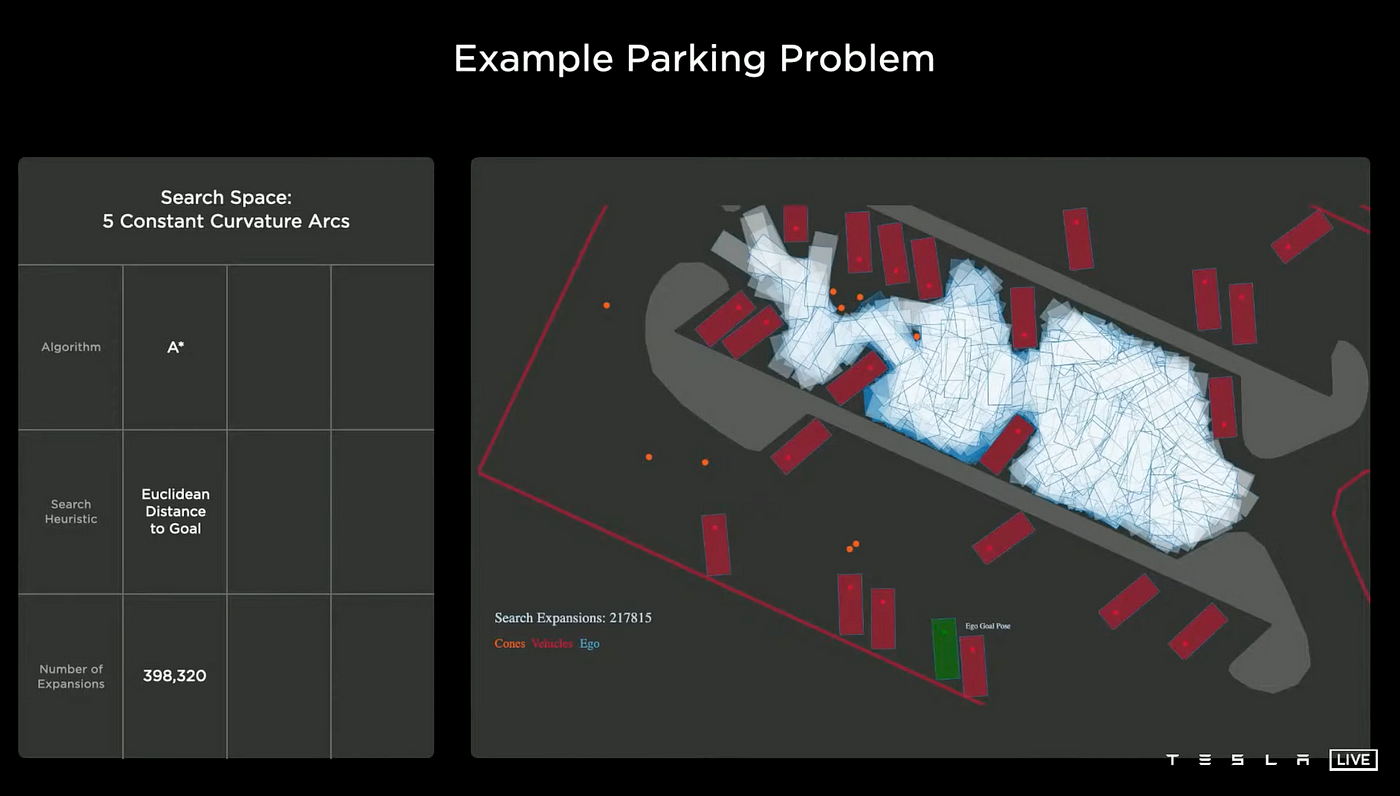
The basic approach employs the A* algorithm, utilizing the euclidean distance as its heuristic function. As can be seen in the image, this method quickly becomes stuck in local minima. Despite eventually reaching its goal, it required excessive computational resources, using almost 400,000 nodes to find the solution.
Using Navigation
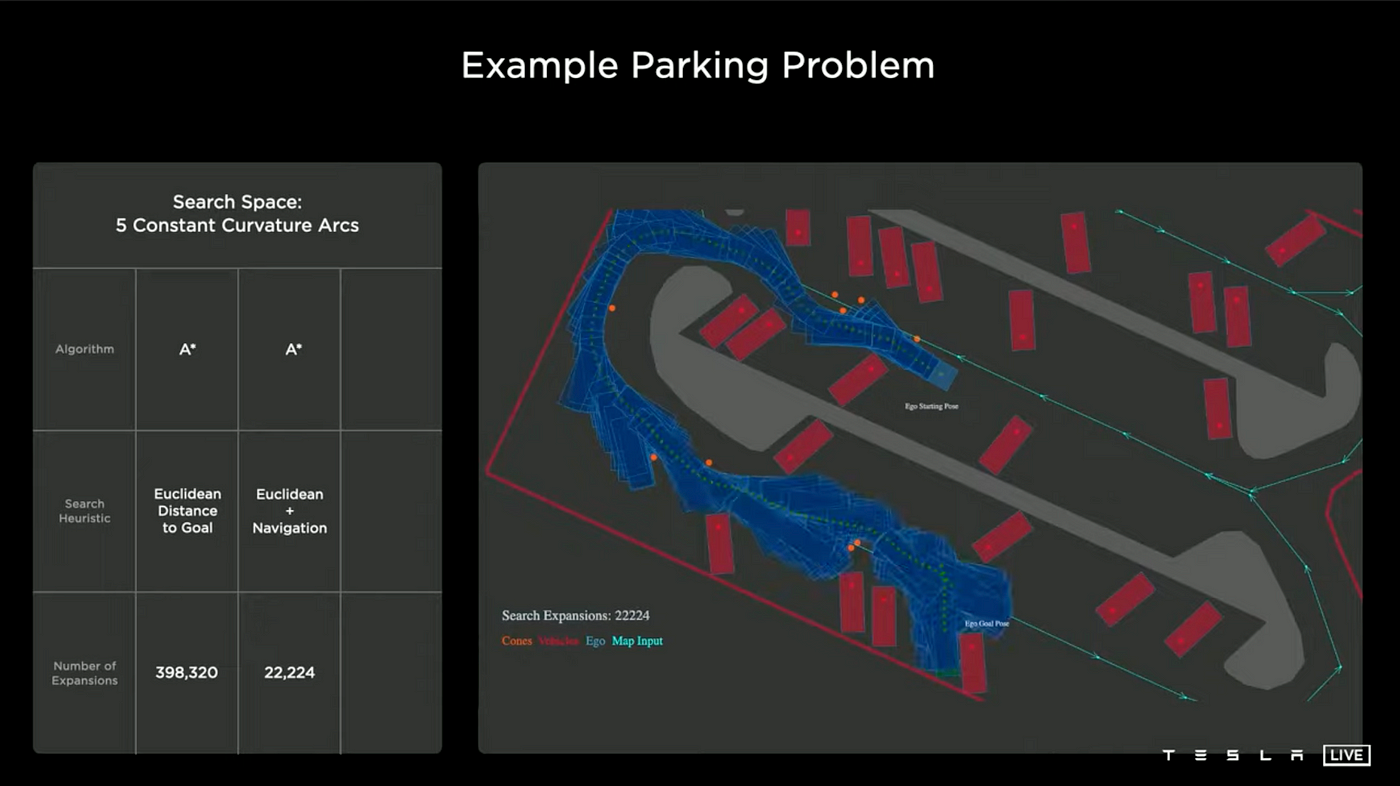
Incorporating a navigation route improves the baseline performance, but when facing obstacles, the approach is similar to before, retracing steps and exploring new paths. However, even with this enhancement it still required 22,000 nodes to find the solution.
Monte Carlo Tree Search
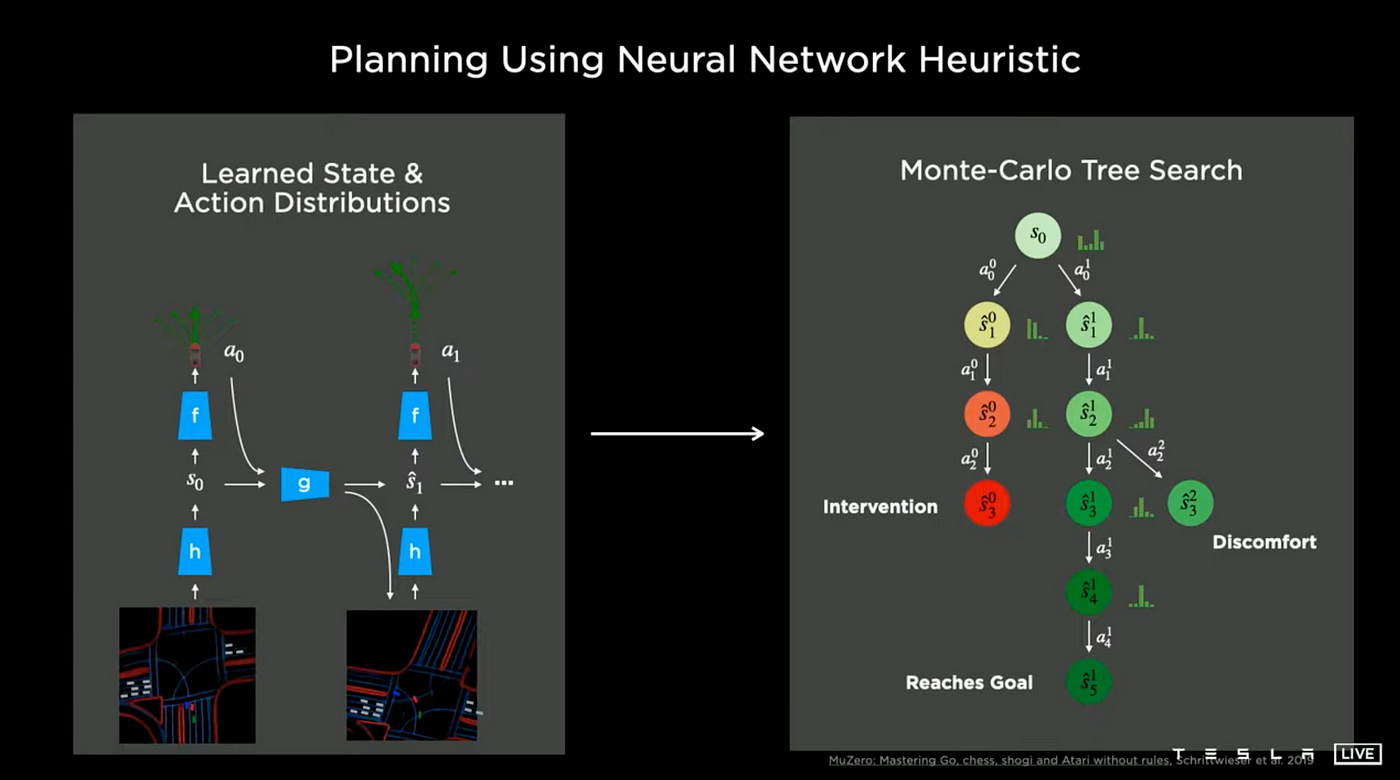
The Tesla AI team is developing neural networks that are able to generate state and action distributions, which can then be integrated into a Monte Carlo tree search algorithm, with different cost functions considered. These cost functions may include specific metrics such as distance, potential collisions, passenger comfort, traversal time, and any manual interventions made by the driver.
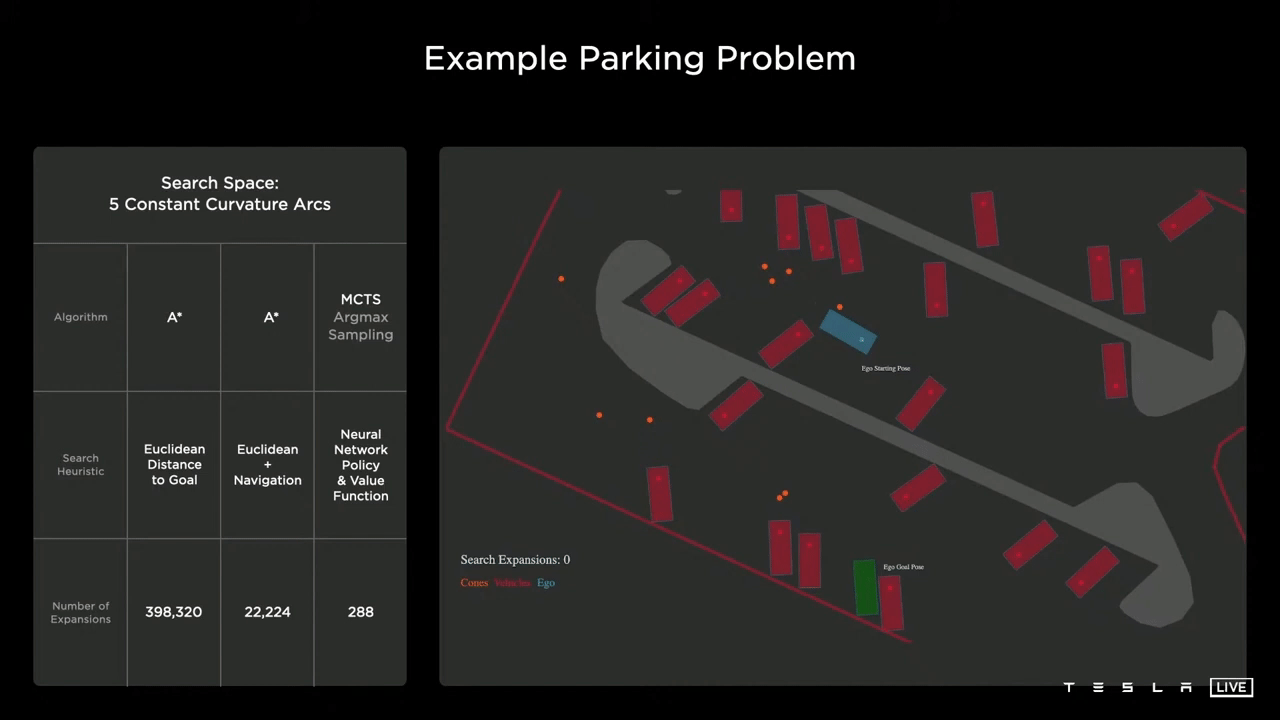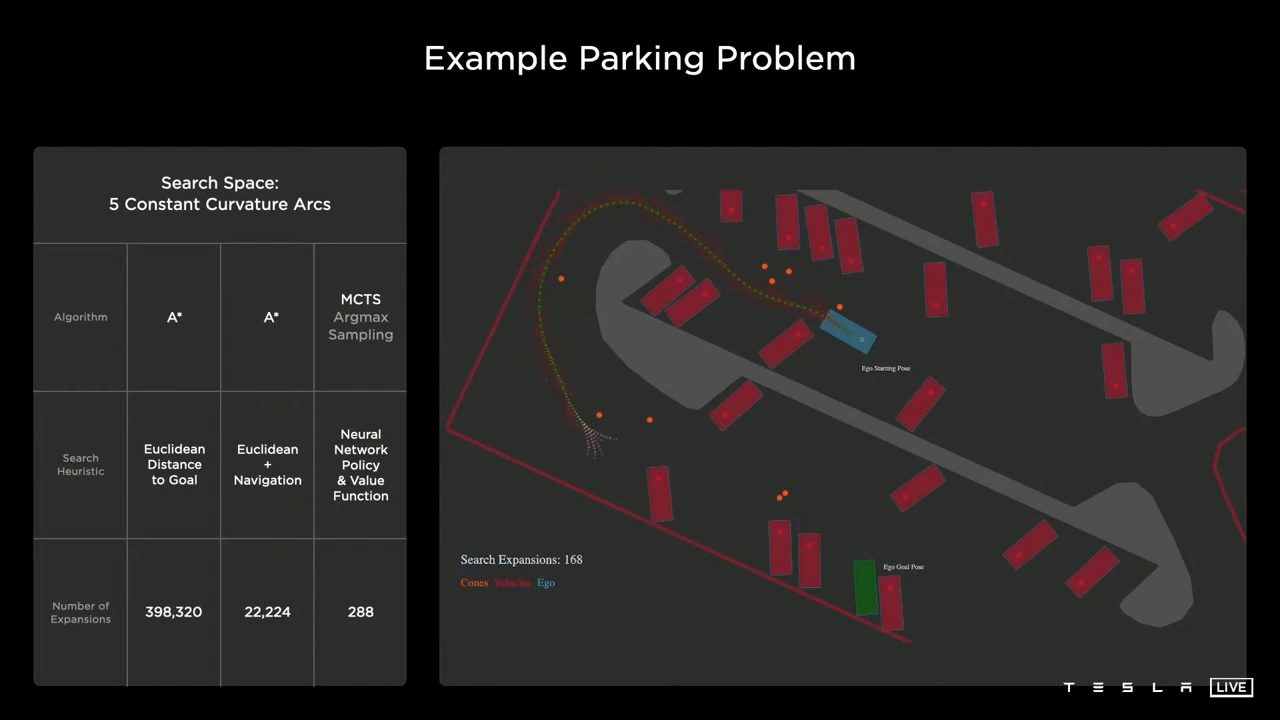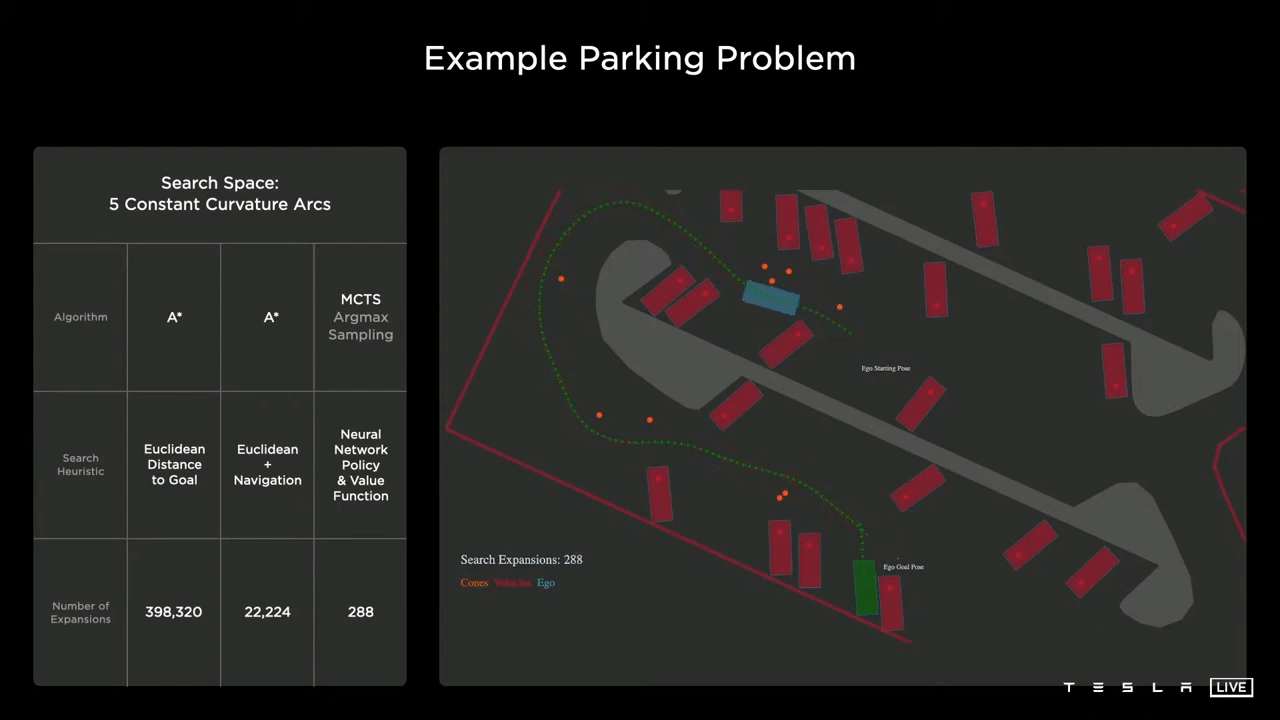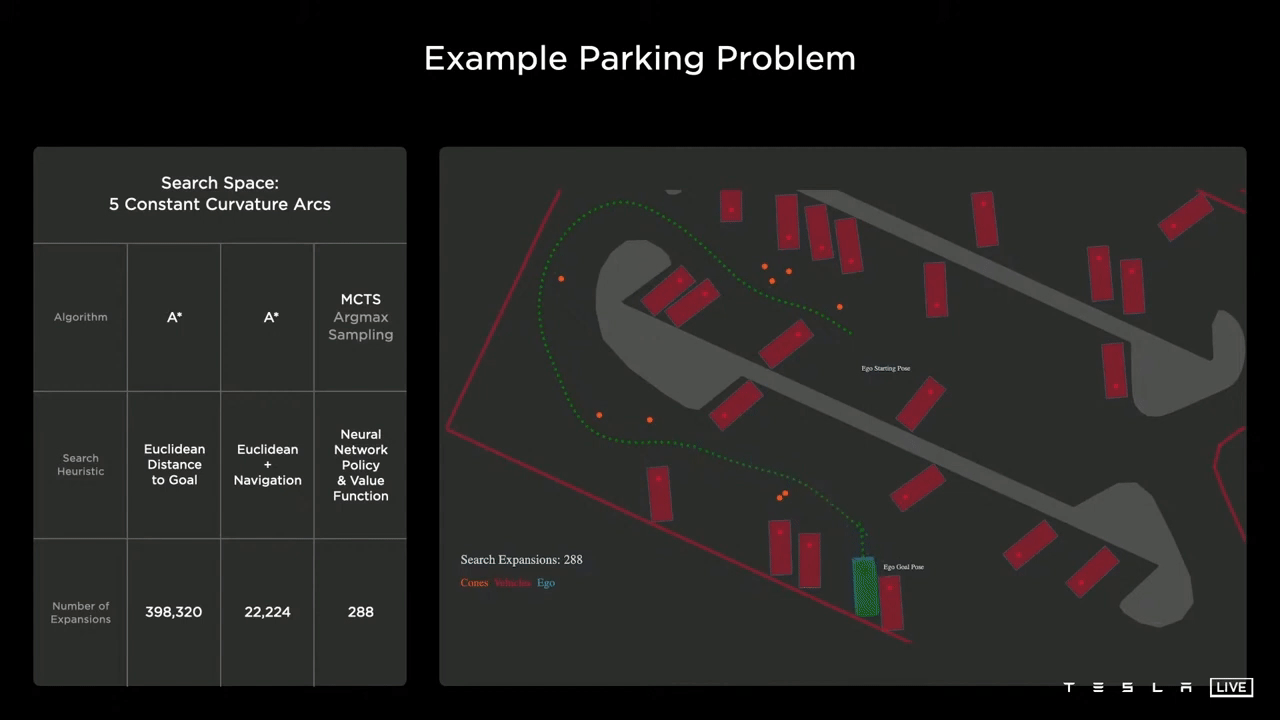
As can be seen in the image, the planner is able to quickly progress toward the goal without the use of a navigation heuristic. The neural network is able to take in the overall context of the scene and generate a value function that effectively guides it toward the optimal solution, rather than getting trapped in any local minima. This results in a significant reduction in computational resources, with the solution found using only 288 nodes.
Tesla has impressive engineering capabilities. The engineers have already integrated AlphaZero and MuZero technologies into their autonomous driving system.
The Final Architecture
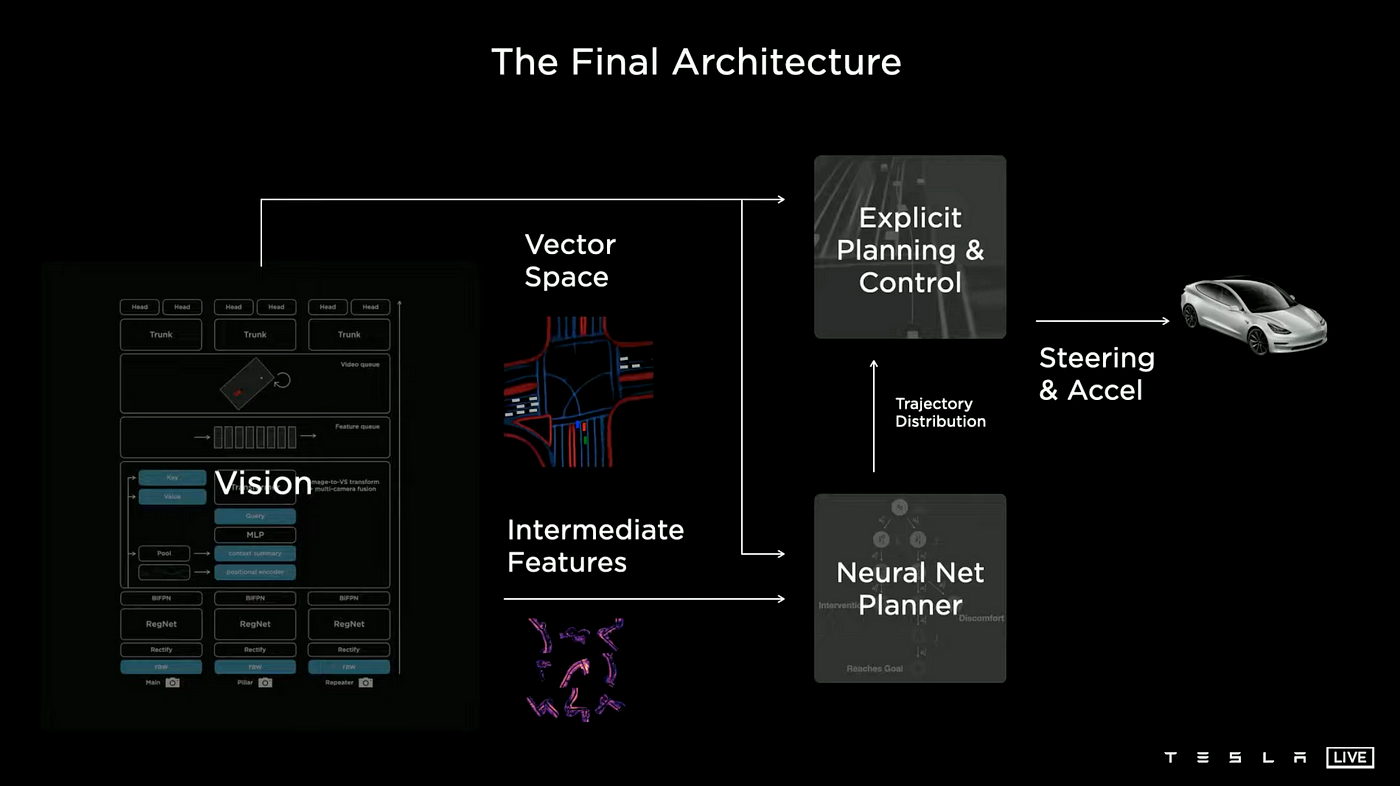
The vision system processes the high volume of video data by converting it into a vector space, which can be utilized by both the explicit planner and the neural network planner. Additionally, the network planner is able to also take in intermediate features generated by the network. This combination of inputs creates a trajectory distribution, which can be optimized in an end-to-end manner, considering explicit cost functions, human interventions, and other imitation data. This output is then fed into an explicit planning function, which determines the optimal steering and acceleration commands for the car.
Part 4
Auto Labeling and Simulation
Training Data
How does Tesla create training data?
- Manual labeling
- Auto labeling
Manual Labeling
Tesla has a 1,000-person in-house data labeling team. Tesla gets training data from its fleet and needs to collect millions of vector space examples that are well-labeled and include various edge cases. 2D image labeling became 3D and 4D labeling.
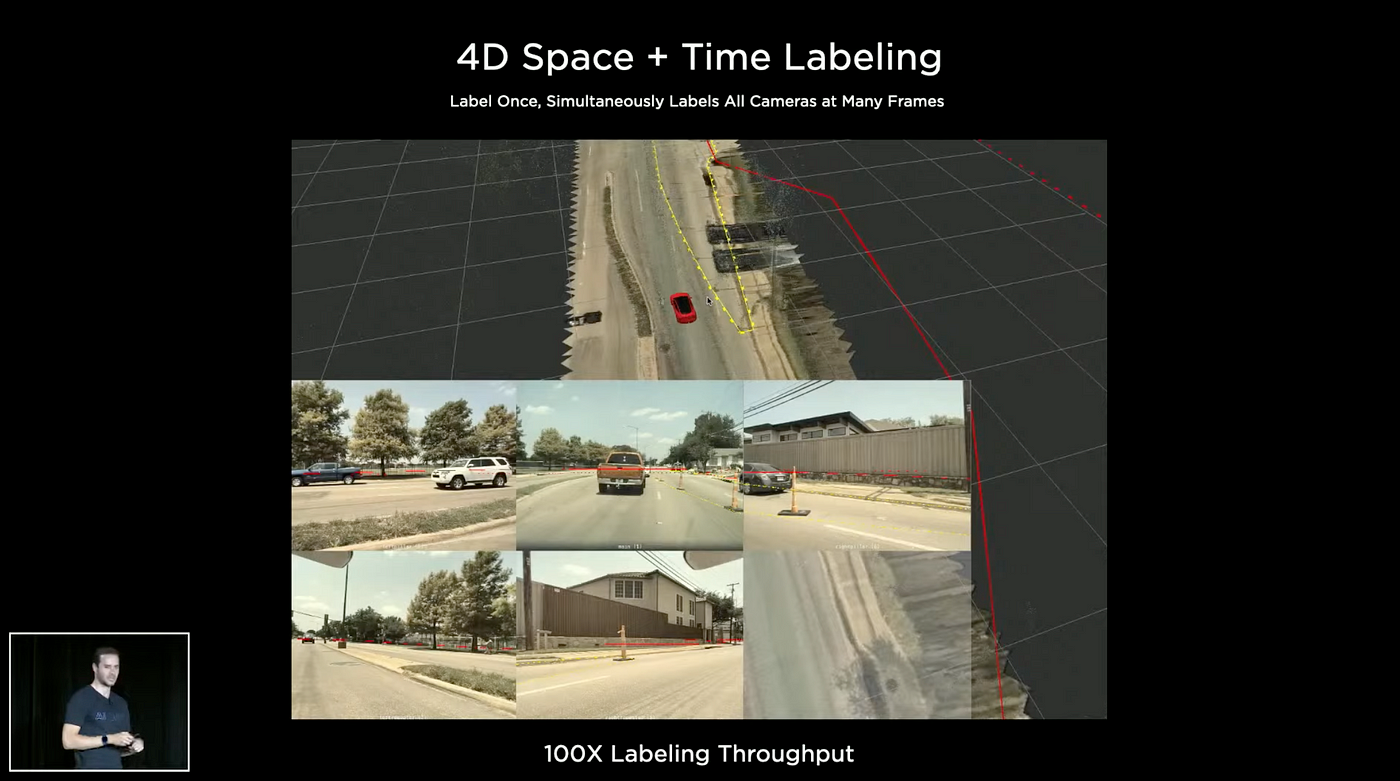
They are directly labeling in vector space, the labeler is changing the labels directly in vector space and then they are automatically projecting those changes into camera images.
The labeler labels directly in vector space. People are better at labeling semantics, but computers are better at geometry, reconstruction, triangulation, and tracking. Auto labeling is the combination of people and computers.
Auto Labeling
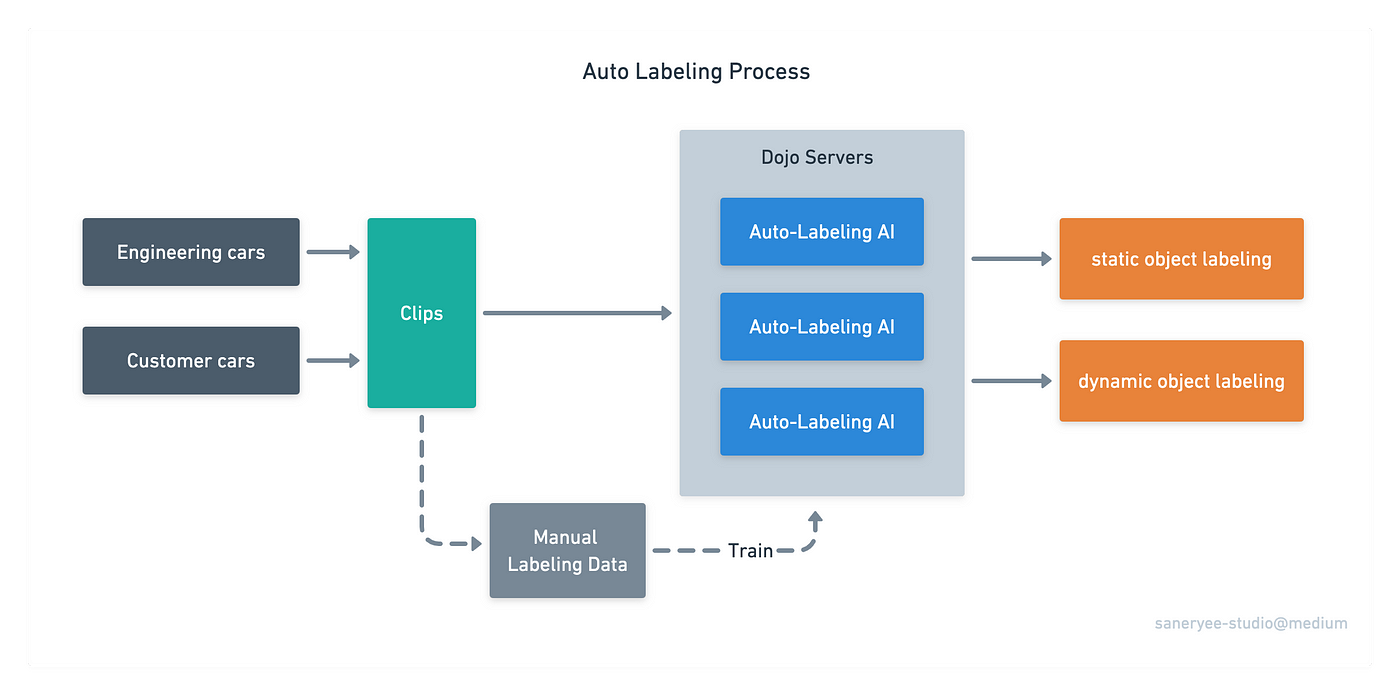
Auto labeling is far more efficient than manual labeling, so Tesla developed a large system to implement it.
Clip
A clip is the smallest unit that Tesla uses for data labeling. It contains video, Inertial Measurement Unit (IMU), GPS, odometry, and other data.

As shown in the image below, Tesla collects clips from engineering cars and customer cars. Then they use auto-labeling AI and manual labeling to train the neural networks.
The 8 cameras on a Tesla EV can provide images of objects from different angles, which can be used for NeRF. NeRF is a way to construct 3D models from 2D images. Tesla uses a NeRF-like network. They input the coordinates of points on the ground and the network outputs a prediction of the road height and populates curb, lane, and other relevant data. Millions of points can be constructed for each example.
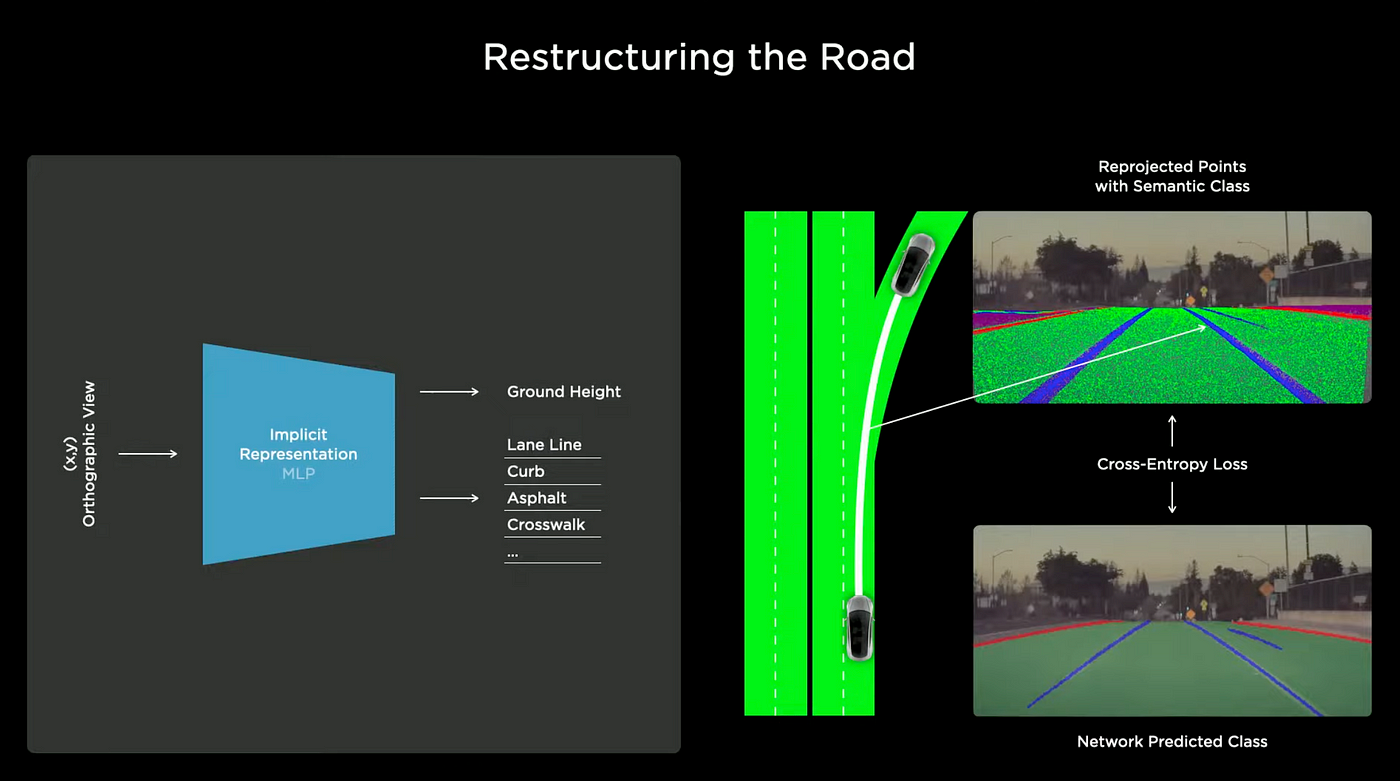
They use cross-entropy loss to ensure accuracy. Once optimization is complete, they have a 3D reconstruction of the road that a computer can understand.
Maps

The image above shows how different cars driving in the same area are used to collect data points on roads in a particular area.
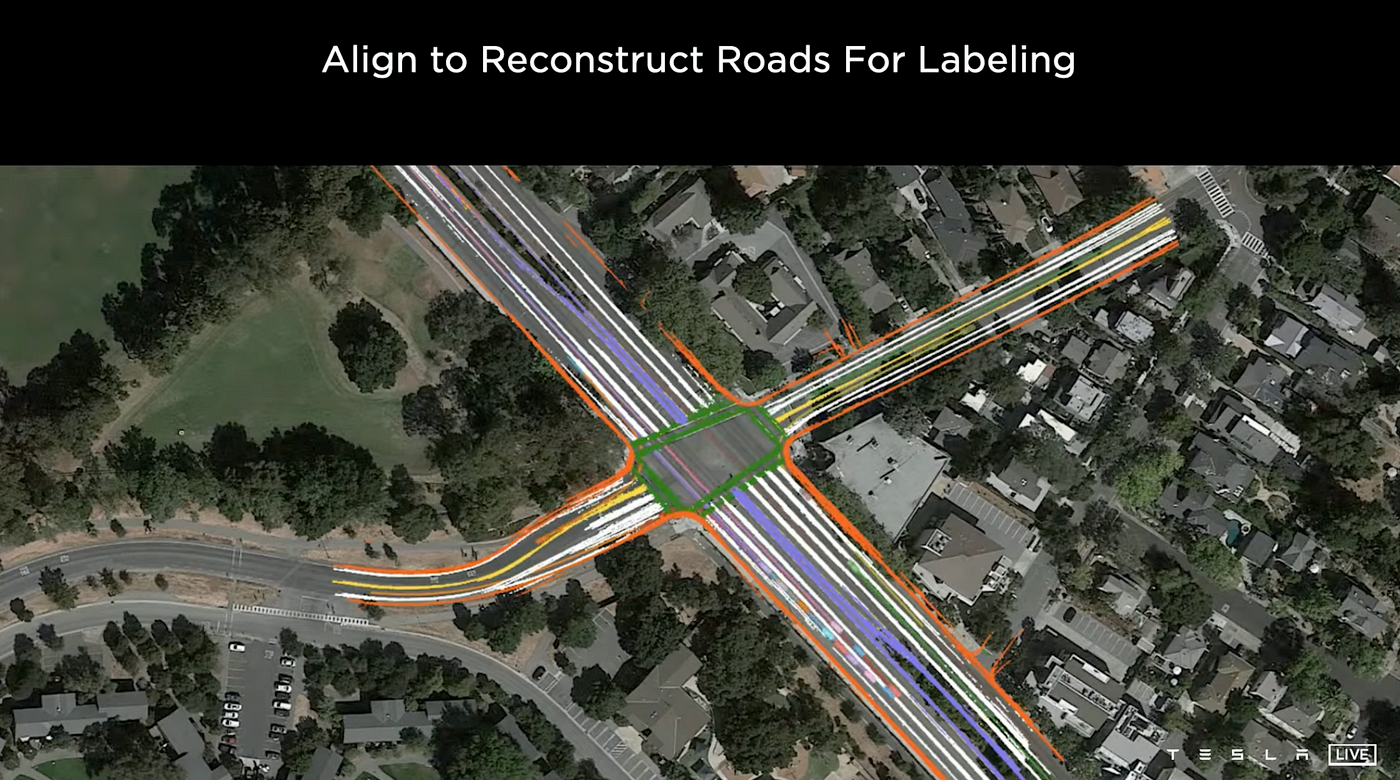
All of the collective data from customer cars are used to create a map of a particular area. This can be thought of as Tesla's "HD map." Useful clips are extracted and auto-labeled.

The system is also able to reconstruct 3D obstacles that are not moving. The point cloud is able to generate points on walls and roads, even if they have no texture. This is an advantage over Lidar, as its point cloud often removes points from objects with no texture. Without that data, it's difficult to label certain objects.
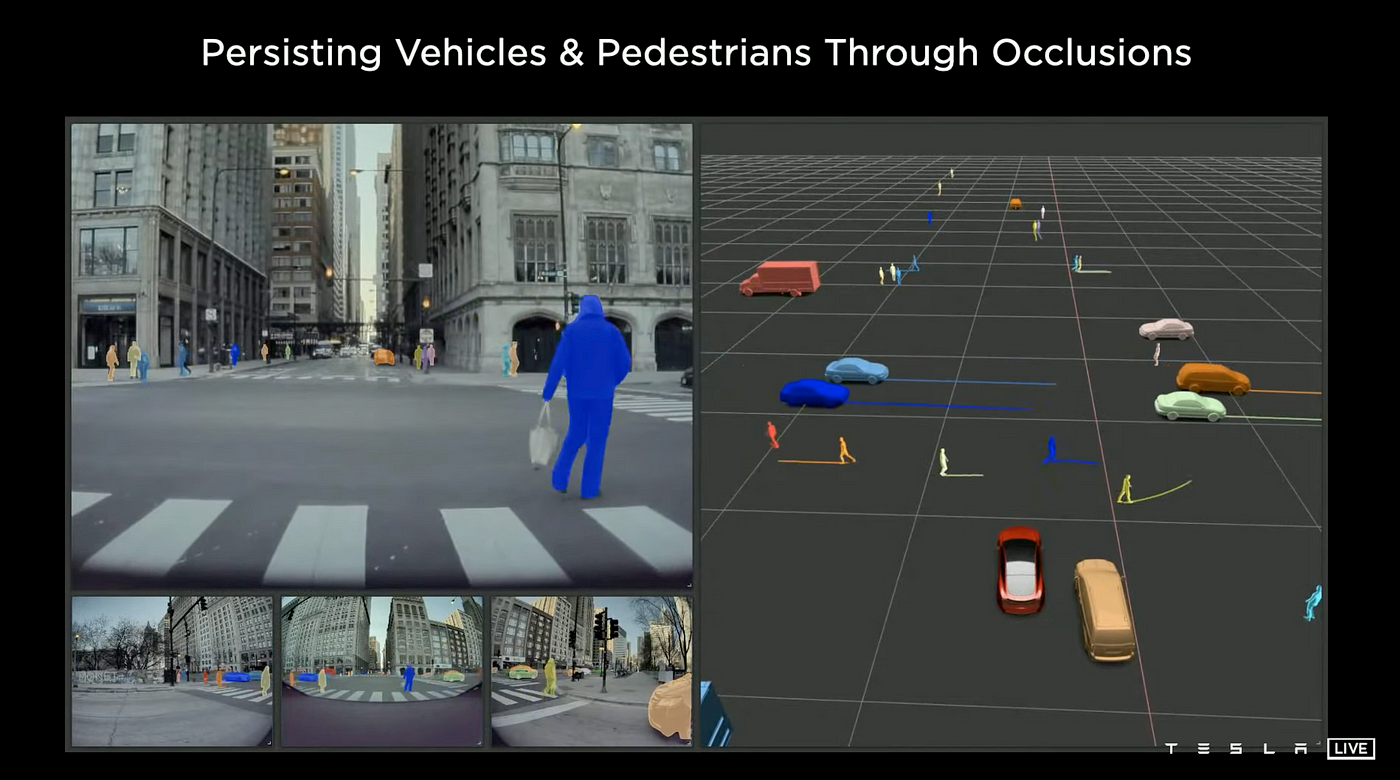
When a clip is added to Tesla's auto-labeling system, it automatically labels static objects and reconstructs them in a 3D scene. Dynamic objects are also automatically labeled and their position, velocity, acceleration, and posture are placed into the 3D vector space.
This processing is done offline, which allows the system to know past and future tracks. Tracks are like a frame of a video. This allows the computer to account for objects (like pedestrians) that need to be tracked but could be visually obscured by a car. This allows for fully annotated spaces even if some objects are obscured in certain tracks.

Remove Radar
Tesla removed the radar from Tesla EVs within 3 months using the auto labeling system. They are confident that only vision (8 cameras) is necessary for level 5 autonomous driving.

In the image above, snow is covering the camera lens, severely obstructing vision. When Tesla first removed radar, the system was not good at handling low-visibility situations like this. That's because the model had not been trained for these situations. To solve this problem, Tesla requested similar situations from the fleet. They got back lots of clips that depict similar situations.

The fleet sent 10,000 clips of similar situations to Tesla. The clips were auto-labeled in a week. With manual labeling, that would have taken 2 or 3 months.
Then Tesla did the same for 200 other low-visibility situations. The model quickly improved and Tesla was able to remove the radar from Tesla EVs.
Simulation
Simulation involves using 3D-rendered graphics to train the neural net in situations that are difficult to obtain from the real world.

The simulation in the clip appears highly realistic and visually appealing, as the ground features various cracks. Additionally, all the objects and their movements depicted in the scene closely resemble those of a real-life setting. It would be difficult to differentiate the virtual clip from a real one.

Using simulated data offers several benefits, such as the ability to utilize vector space, achieve precise labeling including vehicle cuboids with kinematics, depth, surface normals, and segmentation, which can prove useful in cases where manual labeling may be challenging, such as scenarios with many pedestrians crossing the road. Additionally, new labels can be added quickly through the use of code, and simulation can also aid in situations where sourcing real-world data may be difficult, like rare or hard-to-find scenes. Furthermore, the simulation system allows for the testing and verification of closed-loop behaviors, including positioning, perception, prediction, planning, and control.
Accurate Sensor Simulation

Tesla's simulation system aims to generate images that closely resemble those captured by the onboard cameras rather than creating visually stunning scenes. To achieve this, the system models a wide range of properties that are found in real-world cameras, including sensor noise, motion blur, optical distortions, and diffraction patterns caused by the windshield. This simulation system is utilized not only to improve the performance of Tesla's Autopilot software but also in the design and optimization of hardware components such as lenses, cameras, sensor placement, and even headlight transmission properties.
Photorealistic Rendering

In order to create realistic visuals, it is important to minimize the presence of jagged edges. To achieve this, Tesla's simulation system employs neural rendering techniques and utilizes a specialized anti-aliasing algorithm. This algorithm was developed by the Tesla AI team to specifically address this issue. Additionally, ray tracing technology is used to generate realistic lighting and global illumination. These approaches are commonly used in the gaming industry and are employed by Tesla's simulation system to maximize realism in simulated scenes.
Diverse Actors and Locations

To ensure that the AI models developed by the Tesla team do not overly conform to the training data, the team has created a vast library of assets, including thousands of unique vehicles, pedestrians in various attire, props, and even a moose. The team also designed a simulation of 2000 miles of roadways, which is roughly equivalent to the distance between the East and West coasts of the US. To maximize efficiency, they have also developed tools that allow for the construction of several miles of roadway in a single day by a single artist.
Scalable Scenario Generation

The majority of the data used to train Tesla's AI models are generated through algorithms rather than manually by artists. These algorithms are used to create simulation scenarios such as the curvature of the road, various types of trees, cones, poles, cars moving at different speeds, and various types of traffic participants that can be adjusted as needed. The simulation system can also simulate a wide range of natural conditions such as weather and lighting.
The Tesla AI team is not arbitrarily selecting the data, instead, they use machine learning-based techniques to identify the network's failure points and create additional data specifically around these areas. The team is also using Generative Adversarial Network (GAN) in the simulation system which is a form of unsupervised learning. GAN involves two neural networks that are trained in a closed loop with the objective of improving network performance by competing against each other in a 'game'.
Scenario Reconstruction
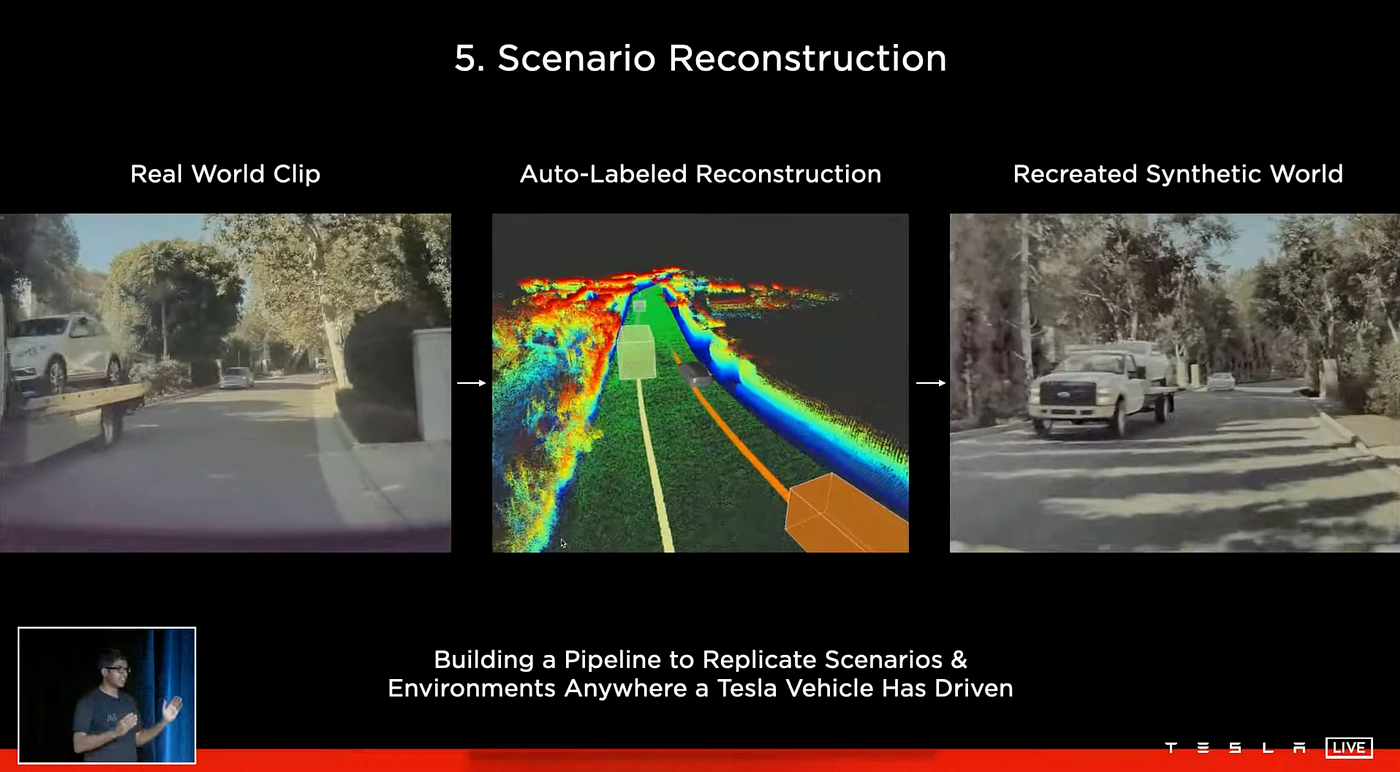
The Tesla AI team aims to recreate any failures that occur with the Autopilot system, as it makes it easy to reproduce the problem within the simulation and identify a solution. To achieve this, the team has developed a pipeline that can replicate scenarios and environments from any location where a Tesla vehicle has been driven. As depicted in the figure, the pipeline starts by collecting real-world footage from a car, which is then processed through an automated labeling system to create a 3D reconstruction of the scene, including all moving objects. With the visual information from the real world, the team then creates a synthetic recreation of the scene and can replay the Autopilot's actions on it. This allows them to identify and solve the problem. Furthermore, they can also generate new scenarios based on the original failure, and continue to train the Autopilot on these new scenarios.
Neural Rendering

Tesla utilizes neural rendering techniques to increase the realism of its simulations. The latest rendering results demonstrate this, as the recreated synthetic simulation scene appears incredibly realistic when compared to the original clip.

Tesla has used a large amount of simulated data to train its AI models, specifically 371 million images with 480 million labels.
Part 5
Updates
This part of the article is based on Tesla's AI Day from September 30, 2022.
Ashok Elluswamy, the director of Tesla AI, opened the presentation and gave us an update on how rapidly FSD is growing. FSD beta went from 2,000 users in 2021 to 160,000 in 2022. Tesla scaled up its training infrastructure by 40-50% – they now have about 14,000 GPUs.
Tesla also stated that it is removing ultrasonic sensors from its Model 3 and Model Y vehicles and will now only have Tesla vision – 8 cameras. The rollout will be completed on all Model 3 and Model Y vehicles globally over the next few months, followed by Model S and Model X vehicles throughout 2023. The new system will give Autopilot improved spatial positioning, visibility, and object identification abilities. Some features will be temporarily limited or inactive during the transition period but will be restored in the near future via software updates.
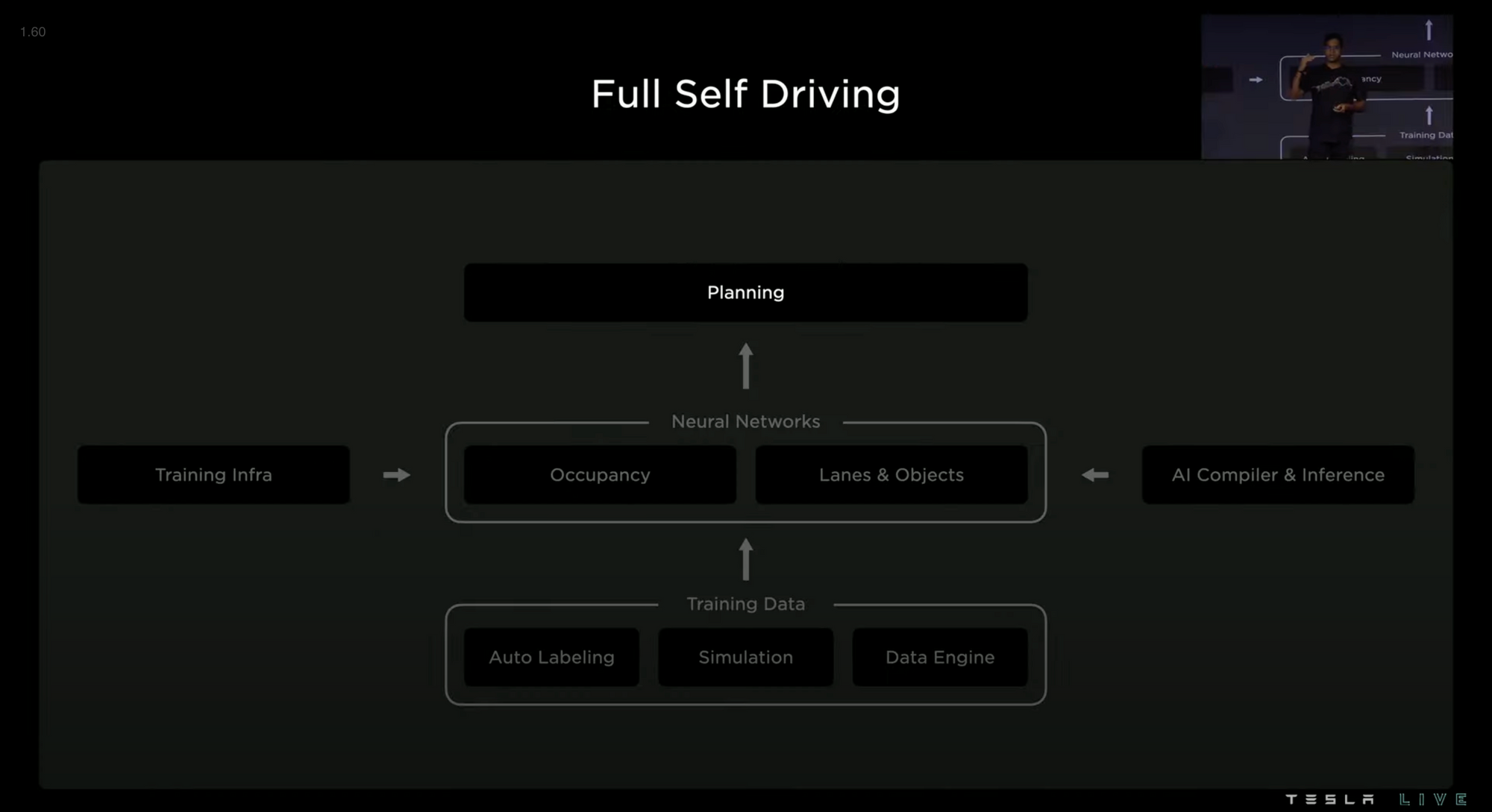
Overview
- Planning (Determining the optimal path for the vehicle to take)
- Occupancy Network (Converting video from 8 cameras into vector space)
- Training Infrastructure (14,000 GPUs: 4,000 for auto labeling and 10,000 for training)
- Lanes and Objects (A system for modeling lane paths, especially at intersections)
- AI Compiler and Inference (Allow vehicles to make real-time decisions and adapt to new situations on the road)
- Auto Labeling (Computers automatically label clips)
- Simulation (Virtualizing real-world streets to simulate data that would be difficult or impossible to collect from the fleet)
- Data Engine (Tesla takes in data from the fleet/simulation and manually overrides challenge cases to improve the neural net)
Planning
In complex situations, there are many possible paths that the vehicle can take. If a passenger is crossing an intersection as the Tesla is making an unprotected left turn, for instance, the Tesla could aggressively go in front of the pedestrian. Or it could wait and go behind the pedestrian. It could also change its path to go around the pedestrian in either direction. These situations become more difficult as the amount of other moving objects increases: there could also be cars crossing the intersection on both sides or traffic coming head-on.
If there are >20 relevant moving objects, the potential relevant interaction combinations quickly increase to, say, >100.
To solve this problem, the EV focuses its compute on the most promising outcomes using a parallelized tree search.
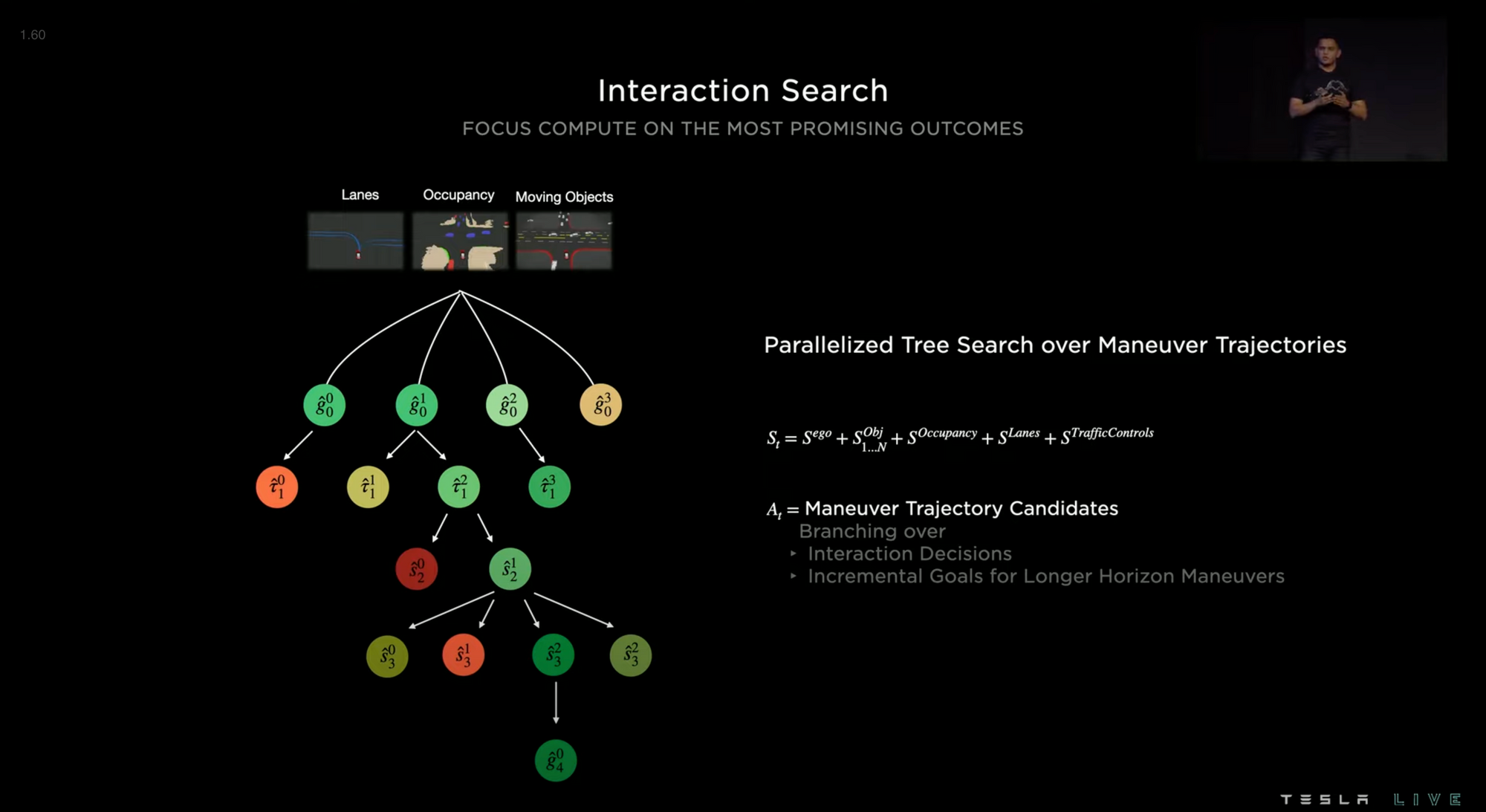
This works by selecting the most pertinent object first. It then determines the best path that would avoid that object, taking the object's trajectory into account. It then moves on to the second most important object and checks if the path also avoids that object. If it does, it moves to the third, and so on, until it finds a path that avoids all relevant objects. This allows the vehicle to move into a crowded street and avoid crashes.
Initially, Tesla used physics-based numerical optimization but it wasn't fast enough at processing actions (~1-5 ms per action). So they developed lightweight queryable networks that were trained on human drivers (data pulled from the Tesla fleet) and offline solvers with relaxed limit times. This greatly reduced runtime to ~100 microseconds per action.
To optimize further, they implemented collision checks, comfort analysis, intervention likelihood, and a human-like discriminator. These are checks to make sure that the system is working properly and not resulting in more collisions or decreased comfort.
Occupancy Network
The occupancy network is Tesla Vision. The 8 cameras around the body of the vehicle are used to create 3D vector space – a model of the world around the vehicle. They use 12-bit raw photos rather than 8-bit because there is more information – 16x better dynamic range and reduced latency.
The occupancy model predicts which objects (and even which part of an object) will move. In the presentation, there is a bus in front of the Tesla. The front of the bus turns blue in the vector space to indicate that the model predicts it will move first. The back of the bus remains red, indicating that it is not yet predicted to move.

As the bus keeps moving, the model predicts it will move and the entire bus turns blue.

Training Infrastructure
The occupancy network was built with 1.44 billion frames and requires 100,000 GPU hours at 90°C. That would take one GPU 100,000 hours to process, so they run multiple GPUs in parallel to reduce the time it takes.
Tesla is using 14,000 GPUs. 4,000 for auto labeling and 10,000 for training.
Lanes and Objects
Tesla autopilot used to use a simple model that worked for straightforward lanes like freeways. To create FSD, the system needs to work for difficult situations like unprotected left turns at complex intersections.
The goal is to be able to route out every lane at an intersection and match it to the corresponding lane on the other side.

Elluswamy notes that this system isn't only for vehicles, it could also be used for Optimus, the humanoid robot that Tesla is developing. Tesla is building a system for modeling pathways.
AI Compiler and Inference
AI compilers play a crucial role in the deployment of machine learning models in Tesla's self-driving cars. These software tools optimize trained models for use on the car's onboard computers, allowing the vehicles to make real-time decisions without the need for a connection to a remote server.
Inference is also an important part of Tesla's self-driving system. When a Tesla car encounters a new object on the road, it uses its machine learning models to predict the likelihood that the object is a pedestrian, a stop sign, or something else. These predictions are then used by the car's decision-making system to navigate the road safely.
By using AI compilers and machine learning for inference, Tesla's self-driving cars are able to constantly learn and adapt to new situations, making them some of the most advanced autonomous vehicles on the road today.
Auto Labeling
It's difficult to turn the vast amount of data collected by the fleet into a form that can be used to train the neural net.
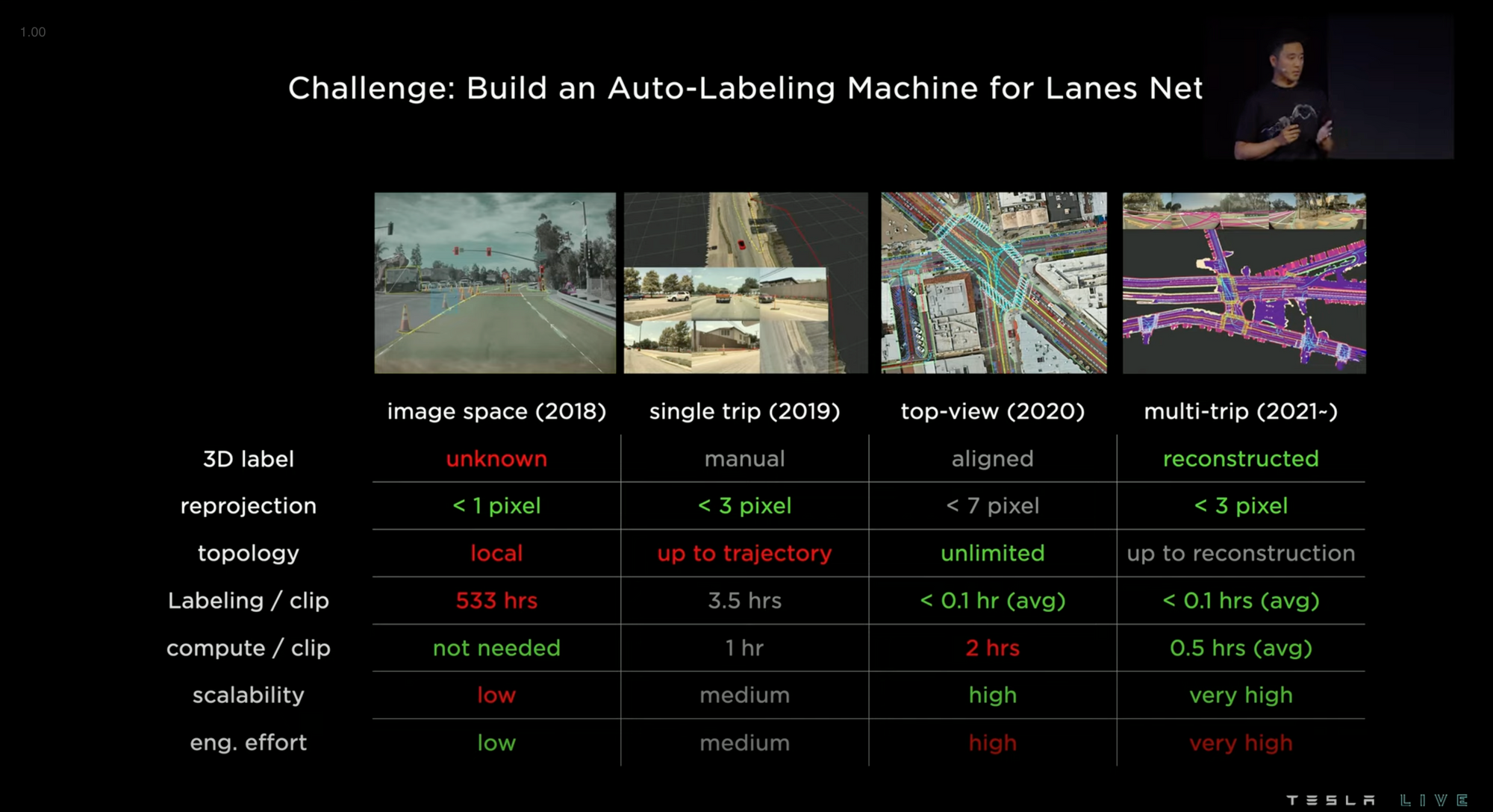
The solution is auto-labeling. For labeling 10,000 trips, auto labeling took 12 hours and is done by computers rather than the 5 million hours of manual labeling that would have been required.
Auto labeling has 3 core parts: high-precision trajectory, multi-trip reconstruction, and auto-labeling new trips.
High precision trajectory means that the vehicles in the fleet accurately understand their relationship to their surroundings and can send that data to Tesla.
Multi-trip reconstruction takes the data from one vehicle and syncs it with the data from another vehicle to make a virtual map of the streets where the fleet has traveled. At the end of the data collection, a human analyst finalizes the label.
Then the system already has labeling data on the trip, so it auto labels.
Simulation
Tesla uses simulations for situations that are difficult to source or hard to label. The problem is that simulations are time-consuming to produce.
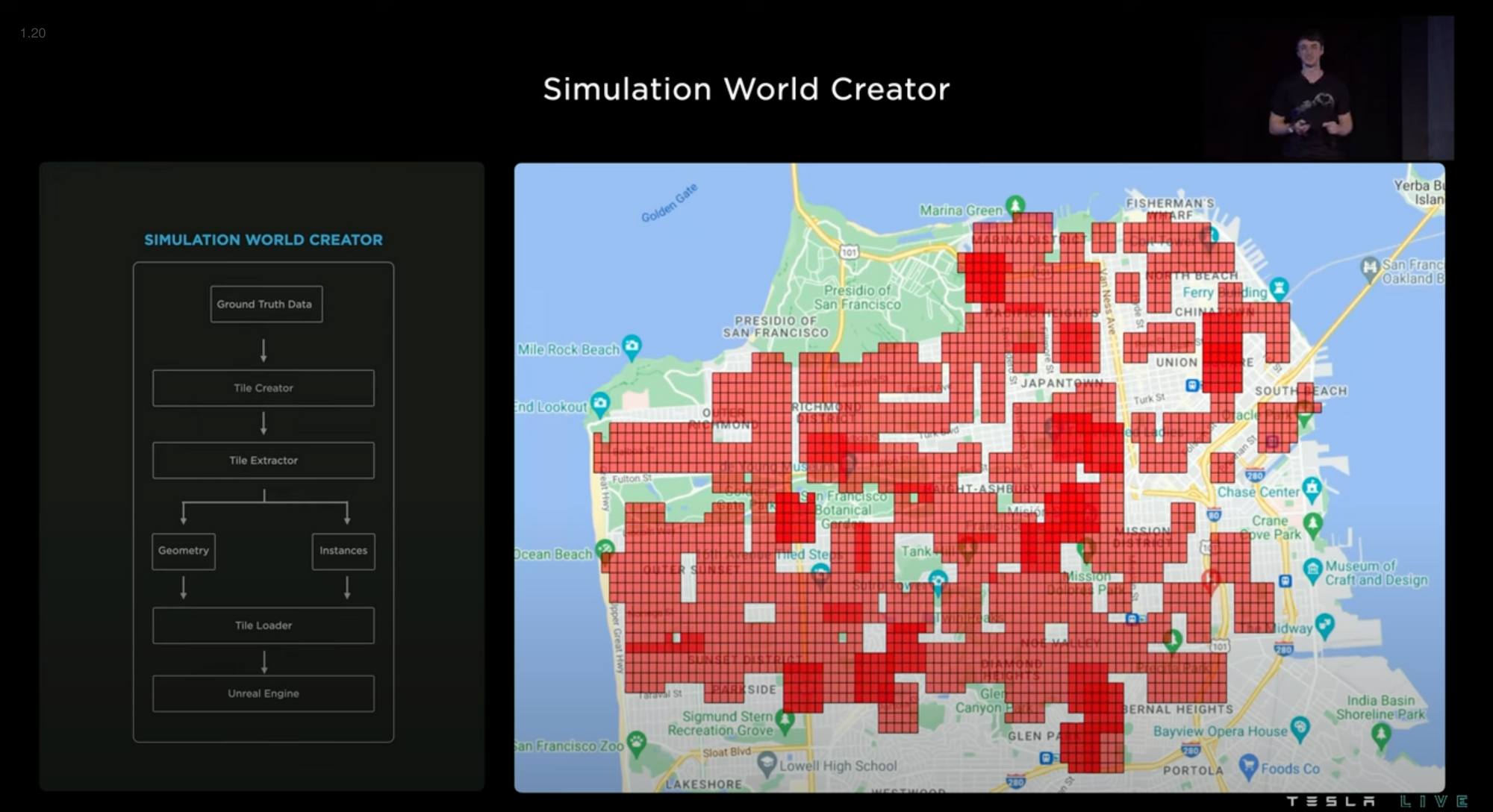
The simulated scene below typically takes 2 weeks to develop, but they now use automated ground truth labels and other tooling to develop similar scenes in 5 minutes.
The ground truth labels come from the auto labels in the previous section.

They can easily change the weather conditions, randomize foliage and obstructions, and change the landscape to either urban, suburban, or rural.
They use Unreal Engine for their simulations.
A single Tesla employee was able to simulate most of San Francisco in 2 weeks.
Data Engine
How Tesla improves its neural networks with data.
The model will sometimes incorrectly predict that a vehicle is waiting for traffic, for instance, when it is actually awkwardly parked. To fix this, a Tesla employee needs to manually override the neural net to help it understand that its prediction was wrong. Over time, the neural net will improve and be able to predict its situation more accurately.
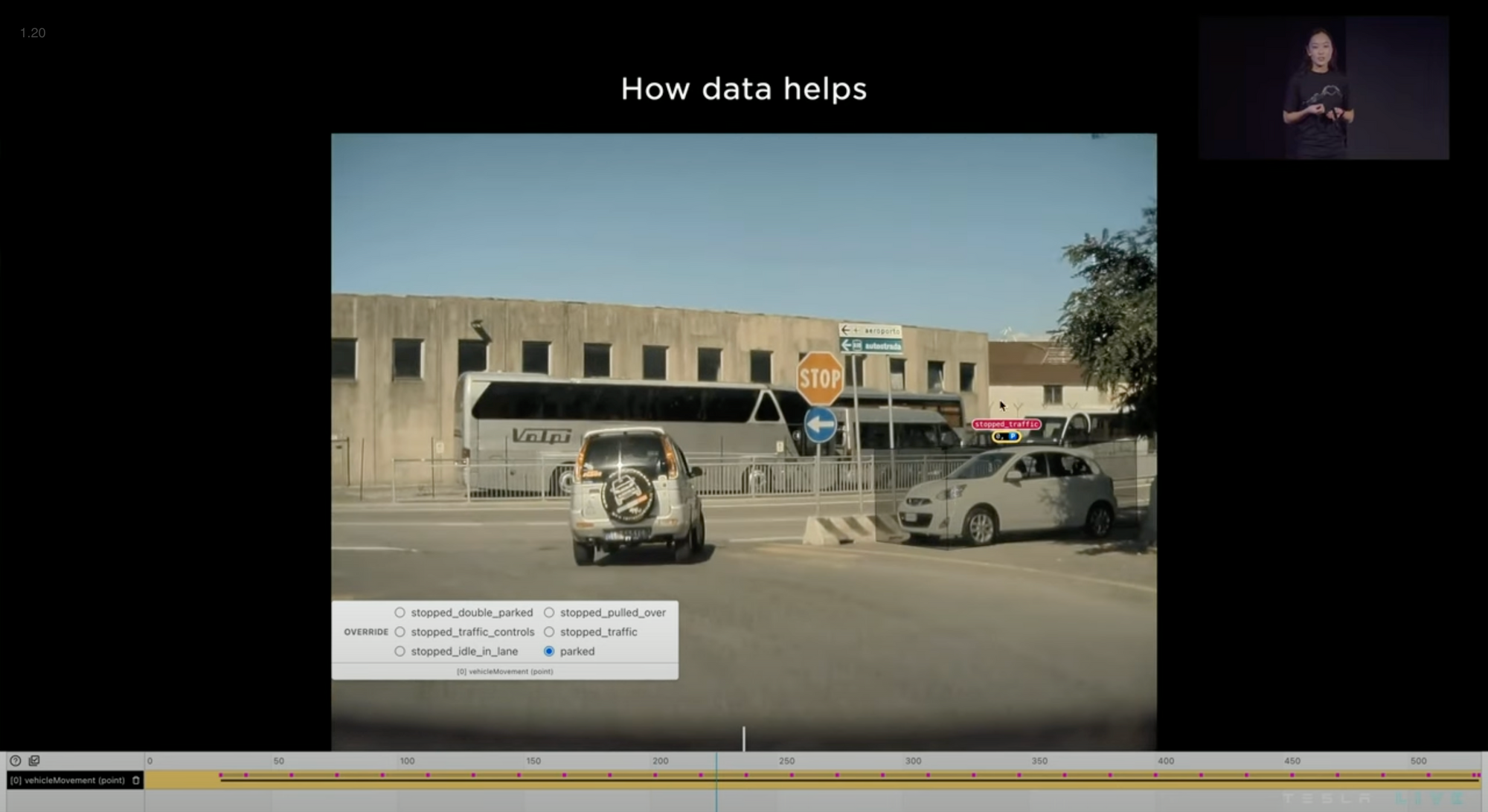
Tesla sources the fleet data for examples similar to the one above and corrects the label. They fixed 13,900 clips at the time of the presentation. The clips are selected based on how poorly the model performs. In other words, they only look for situations where the model performs poorly, in order to improve its weaknesses.
The architecture doesn't even need to be updated. Simply overriding the labels will teach the neural net how to improve. Manually overridden clips are the evaluation set. As the training and evaluation sets grow, the accuracy of the vehicle's movement improves.
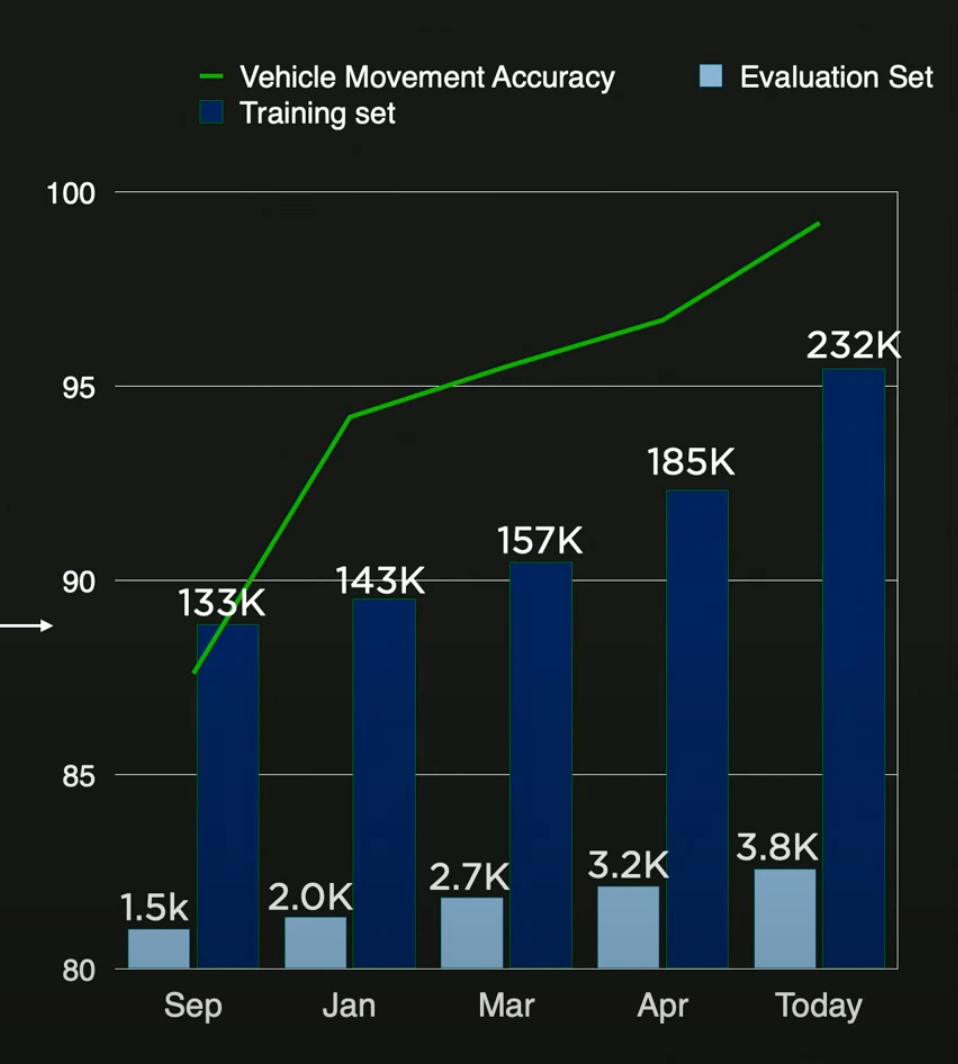
Some of the key challenge cases are parked vehicles at turns, buses and large trucks, leading stopped vehicles, vehicles on curvy roads, and vehicles in parking lots.
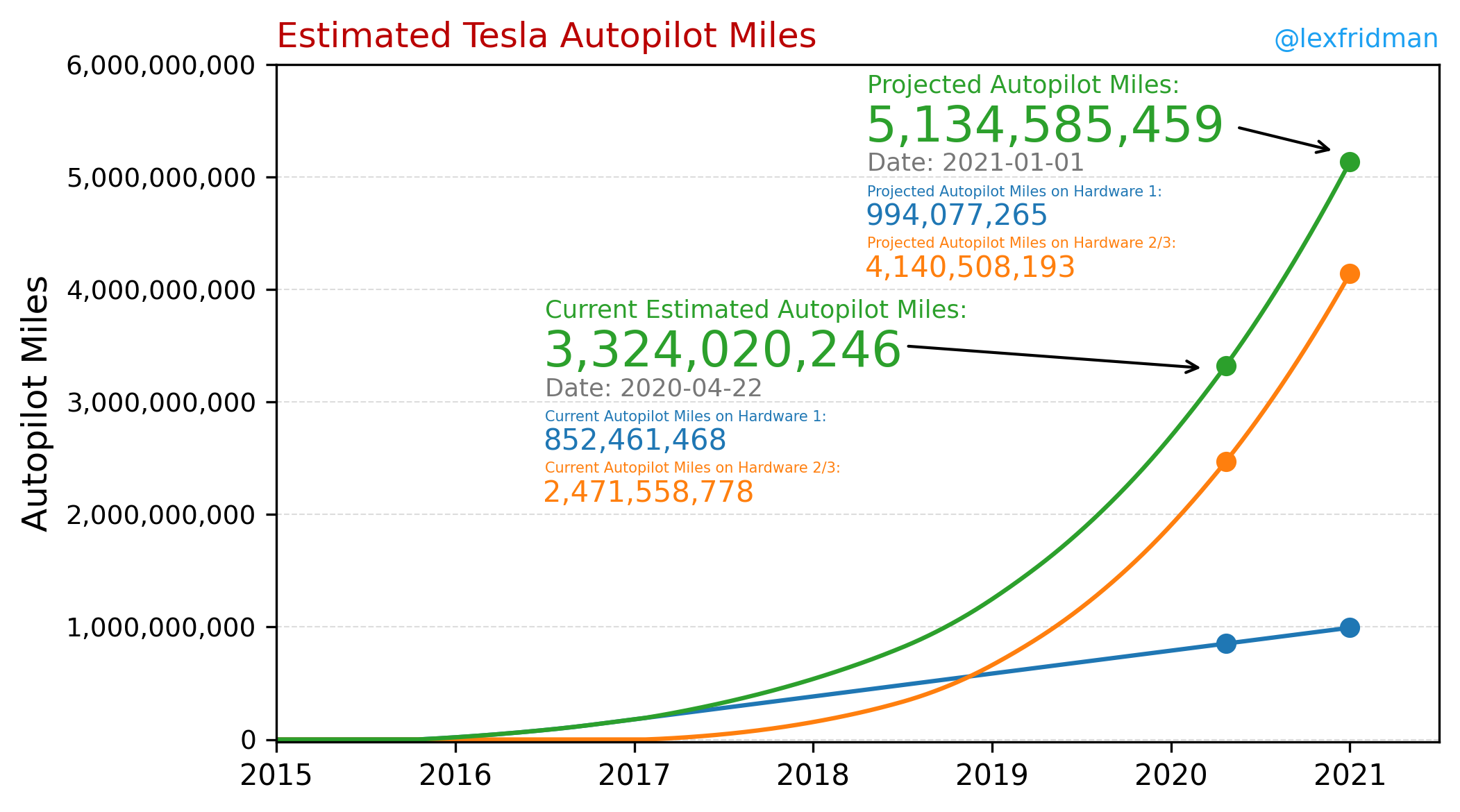
AI researcher, Lex Fridman, projected Tesla's autopilot miles in 2020. In 2020, Tesla had over 3 billion real-world miles. In contrast, Waymo, Google's self-driving project, has only 20+ million real-world miles in 2022.
Part 6
Dojo
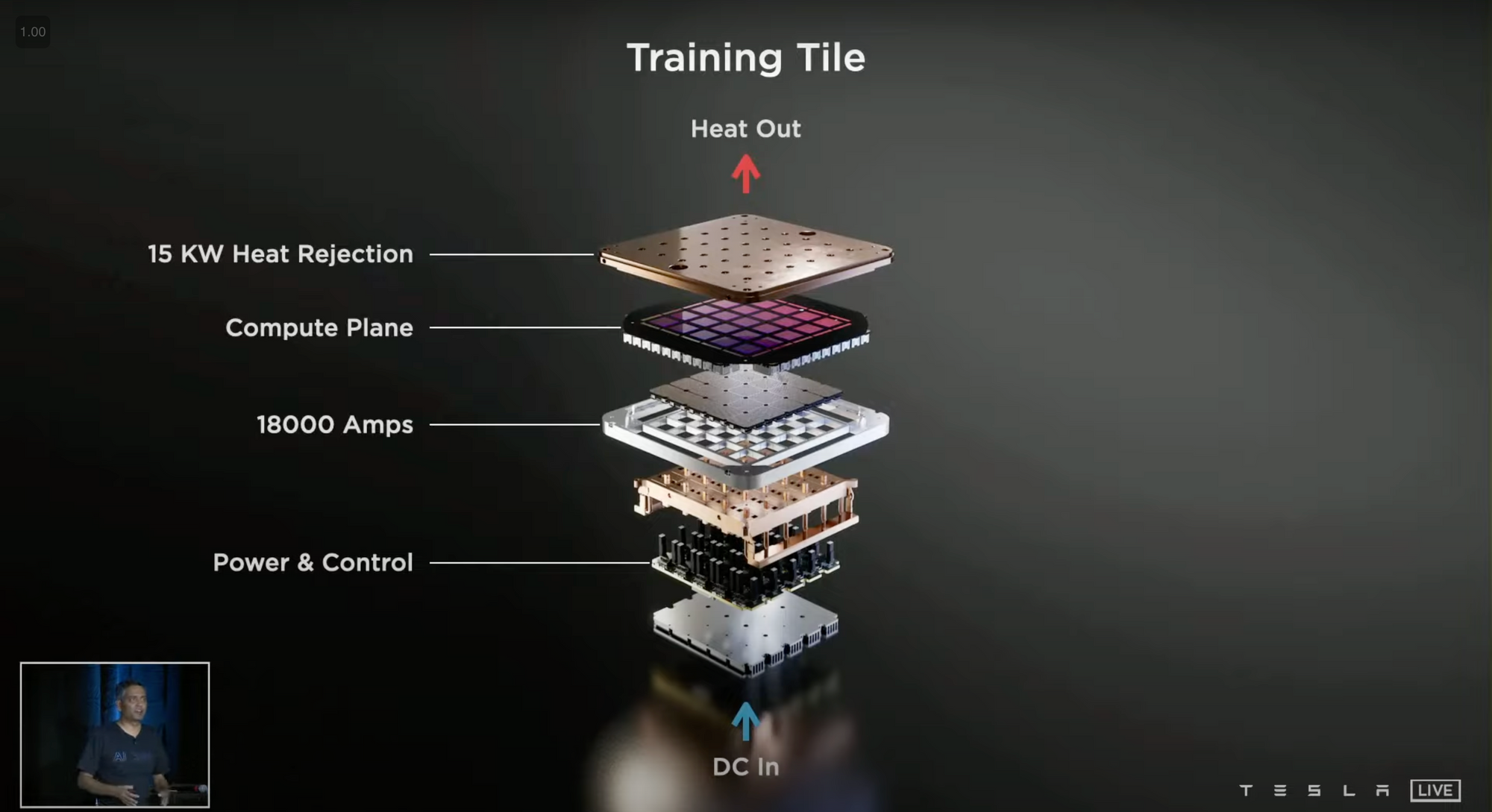
Tesla's FSD neural networks predict the identity of objects, and in order to improve the accuracy of these predictions, multiple predictions must be made and then verified. To train the neural network, a person must check if the prediction made by the network is correct, and if not, the person must manually label the object correctly. For instance, if the network incorrectly predicts a stop sign as a slow sign, a manual labeler would have to correct this by assigning the appropriate label for the stop sign. However, manual labeling is costly and inefficient, as it requires many frames and objects to be labeled. To address this issue, Tesla developed its own supercomputer, named Dojo, as a solution.
What is Dojo?
Dojo is an advanced neural network training computer, which is designed to process large amounts of data and conduct extensive unsupervised training for neural networks. Essentially, Dojo acts as an automated "human labeler" that oversees the prediction process, significantly increasing the learning speed of neural networks. Currently, when Tesla collects data or visuals, Dojo pre-labels many objects in the frames, allowing human labelers to focus on correcting any errors made by Dojo rather than starting the labeling process from scratch. As a result, Dojo significantly reduces the cost of computation and labeling.
Self-Supervised Training
When a Tesla vehicle captures visual data, Dojo has the ability to transform one frame into a 3D video animation. This allows the neural networks to have a full sequence of data, including the ability to see forward and backward, instead of just one frame. This capability allows Dojo to enable self-supervised training for the neural networks. For example, the neural network can make a prediction in the first frame of the visual data, and then self-check its prediction in frame 20. This process can be repeated many times across all collected visuals, significantly increasing the speed of learning.
Object Location Understanding
Another advantage of Dojo is that it enables neural networks to understand the location of objects in relation to other objects. For instance, if there is a person walking on a street from frame 1 to 120, and in frame 121, the person is now obscured behind a parked car, without Dojo, the neural network would not be able to tell that the person is still present as they are obscured by the car. With Dojo, the neural network can infer that in frame 120 the person was beside the car and in frame 121, the person must be behind the car because they cannot disappear within one frame.
Sources and Further Reading
- Tesla AI Day August 19, 2021
- Tesla AI Day September 30, 2022
- Deep Learning by Ian Goodfellow, et al.
- Scaled ML Karpathy presentation: https://youtu.be/hx7BXih7zx8
- https://saneryee-studio.medium.com/deep-understanding-tesla-fsd-part-1-hydranet-1b46106d57
- https://saneryee-studio.medium.com/deep-understanding-tesla-fsd-part-2-vector-space-2964bfc10b17
- https://saneryee-studio.medium.com/deep-understanding-tesla-fsd-part-3-planning-control-9a25cc6d04f0
- https://saneryee-studio.medium.com/deep-understanding-tesla-fsd-part-4-auto-labeling-simulation-60c9bfd3bcb5
- FSD beta version history: https://www.findmyelectric.com/blog/tesla-fsd-beta-full-self-driving-explained/
- Updated version history: https://teslamotorsclub.com/tmc/threads/fsd-beta-release-history.261326/
- Tesla Vision-only after Oct 2022: https://www.tesla.com/support/transitioning-tesla-vision
- Model 3 owners manual (autopilot): https://www.tesla.com/ownersmanual/model3/en_jo/GUID-EDA77281-42DC-4618-98A9-CC62378E0EC2.html
- Read this for simulation news and AI day 2022 info: https://driveteslacanada.ca/news/ai-day-2022-fsd-simplified/
- Facebook RegNet research paper: https://arxiv.org/pdf/2003.13678.pdf
- Musk Tweet FSD: https://twitter.com/elonmusk/status/1609313412131037193?s=46&t=5j4eAYqI4DyklPzJjDoHrg



Comments ()